{
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"id": "756b572d",
"metadata": {},
"source": [
"<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
"\n",
"# <!-- TITLE --> [DDPM1] - Fashion MNIST Generation with DDPM\n",
"<!-- DESC --> Diffusion Model example, to generate Fashion MNIST images.\n",
"\n",
"<!-- AUTHOR : Hatim Bourfoune (CNRS/IDRIS), Maxime Song (CNRS/IDRIS) -->\n",
"\n",
"## Objectives :\n",
" - Understanding and implementing a **Diffusion Model** neurals network (DDPM)\n",
"\n",
"The calculation needs being important, it is preferable to use a very simple dataset such as MNIST to start with. \n",
"...MNIST with a small scale (need to adapt the code !) if you haven't a GPU ;-)\n",
"\n",
"\n",
"## Acknowledgements :\n",
"This notebook was heavily inspired by this [article](https://huggingface.co/blog/annotated-diffusion) and this [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/annotated_diffusion.ipynb#scrollTo=5153024b). "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "54a15542",
"metadata": {},
"outputs": [],
"source": [
"import math\n",
"from inspect import isfunction\n",
"from functools import partial\n",
"import random\n",
"import IPython\n",
"\n",
"import matplotlib.pyplot as plt\n",
"from tqdm.auto import tqdm\n",
"from einops import rearrange\n",
"\n",
"import torch\n",
"from torch import nn, einsum\n",
"import torch.nn.functional as F\n",
"from datasets import load_dataset, load_from_disk\n",
"\n",
"from torchvision import transforms\n",
"from torchvision.utils import make_grid\n",
"from torch.utils.data import DataLoader\n",
"import numpy as np\n",
"from PIL import Image\n",
"from torch.optim import Adam\n",
"\n",
"from torchvision.transforms import Compose, ToTensor, Lambda, ToPILImage, CenterCrop, Resize\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a854c28a",
"metadata": {},
"outputs": [],
"source": [
"DEVICE = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
"\n",
"# Reproductibility\n",
"torch.manual_seed(53)\n",
"random.seed(53)\n",
"np.random.seed(53)"
]
},
{
"cell_type": "markdown",
"id": "e33f10db",
"metadata": {},
"source": [
"## Create dataset\n",
"We will use the library HuggingFace Datasets to get our Fashion MNIST. If you are using Jean Zay, the dataset is already downloaded in the DSDIR, so you can use the code as it is. If you are not using Jean Zay, you should use the function load_dataset (commented) instead of load_from_disk. It will automatically download the dataset if it is not downloaded already."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "918c0138",
"metadata": {},
"outputs": [],
"source": [
"dataset = load_dataset(\"fashion_mnist\") \n",
"dataset"
]
},
{
"cell_type": "markdown",
"id": "cfe4d4f5",
"metadata": {},
"source": [
"As you can see the dataset is composed of two subparts: train and test. So the dataset is already split for us. We'll use the train part for now. <br/>\n",
"We can also see that the dataset as two features per sample: 'image' corresponding to the PIL version of the image and 'label' corresponding to the class of the image (shoe, shirt...). We can also see that there are 60 000 samples in our train dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2280400d",
"metadata": {},
"outputs": [],
"source": [
"train_dataset = dataset['train']\n",
"train_dataset[0]"
]
},
{
"cell_type": "markdown",
"id": "7978ad3d",
"metadata": {},
"source": [
"Each sample of a HuggingFace dataset is a dictionary containing the data."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "0d157e11",
"metadata": {},
"outputs": [],
"source": [
"image = train_dataset[0]['image']\n",
"image"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5dea3e5a",
"metadata": {},
"outputs": [],
"source": [
"image_array = np.asarray(image, dtype=np.uint8)\n",
"print(f\"shape of the image: {image_array.shape}\")\n",
"print(f\"min: {image_array.min()}, max: {image_array.max()}\")"
]
},
{
"cell_type": "markdown",
"id": "f86937e9",
"metadata": {},
"source": [
"We will now create a function that get the Fashion MNIST dataset needed, apply all the transformations we want on it and encapsulate that dataset in a dataloader."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e646a7b1",
"metadata": {},
"outputs": [],
"source": [
"# load hugging face dataset from the DSDIR\n",
"def get_dataset(data_path, batch_size, test = False):\n",
" \n",
" dataset = load_from_disk(data_path)\n",
" # dataset = load_dataset(data_path) # Use this one if you're not on Jean Zay\n",
"\n",
" # define image transformations (e.g. using torchvision)\n",
" transform = Compose([\n",
" transforms.RandomHorizontalFlip(), # Data augmentation\n",
" transforms.ToTensor(), # Transform PIL image into tensor of value between [0,1]\n",
" transforms.Lambda(lambda t: (t * 2) - 1) # Normalize values between [-1,1]\n",
" ])\n",
"\n",
" # define function for HF dataset transform\n",
" def transforms_im(examples):\n",
" examples['pixel_values'] = [transform(image) for image in examples['image']]\n",
" del examples['image']\n",
" return examples\n",
"\n",
" dataset = dataset.with_transform(transforms_im).remove_columns('label') # We don't need it \n",
" channels, image_size, _ = dataset['train'][0]['pixel_values'].shape\n",
" \n",
" if test:\n",
" dataloader = DataLoader(dataset['test'], batch_size=batch_size)\n",
" else:\n",
" dataloader = DataLoader(dataset['train'], batch_size=batch_size, shuffle=True)\n",
"\n",
" len_dataloader = len(dataloader)\n",
" print(f\"channels: {channels}, image dimension: {image_size}, len_dataloader: {len_dataloader}\") \n",
" \n",
" return dataloader, channels, image_size, len_dataloader"
]
},
{
"cell_type": "markdown",
"id": "413a3fea",
"metadata": {},
"source": [
"We choose the parameters and we instantiate the dataset:"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "918233da",
"metadata": {},
"outputs": [],
"source": [
"# Dataset parameters\n",
"batch_size = 64\n",
"data_path = \"/gpfsdswork/dataset/HuggingFace/fashion_mnist/fashion_mnist/\"\n",
"# data_path = \"fashion_mnist\" # If you're not using Jean Zay"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "85939f9d",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"train_dataloader, channels, image_size, len_dataloader = get_dataset(data_path, batch_size)\n",
"\n",
"batch_image = next(iter(train_dataloader))['pixel_values']\n",
"batch_image.shape"
]
},
{
"cell_type": "markdown",
"id": "104db929",
"metadata": {},
"source": [
"We also create a function that allows us to see a batch of images:"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "196370c2",
"metadata": {},
"outputs": [],
"source": [
"def normalize_im(images):\n",
" shape = images.shape\n",
" images = images.view(shape[0], -1)\n",
" images -= images.min(1, keepdim=True)[0]\n",
" images /= images.max(1, keepdim=True)[0]\n",
" return images.view(shape)\n",
"\n",
"def show_images(batch):\n",
" plt.imshow(torch.permute(make_grid(normalize_im(batch)), (1,2,0)))\n",
" plt.show()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "96334e60",
"metadata": {},
"outputs": [],
"source": [
"show_images(batch_image[:])"
]
},
{
"cell_type": "markdown",
"id": "1befee67",
"metadata": {},
"source": [
"## Forward Diffusion\n",
"The aim of this part is to create a function that will add noise to any image at any step (following the DDPM diffusion process)."
]
},
{
"cell_type": "markdown",
"id": "231629ad",
"metadata": {},
"source": [
"### Beta scheduling\n",
"First, we create a function that will compute every betas of every steps (following a specific shedule). We will only create a function for the linear schedule (original DDPM) and the cosine schedule (improved DDPM):"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "0039d38d",
"metadata": {},
"outputs": [],
"source": [
"# Different type of beta schedule\n",
"def linear_beta_schedule(timesteps, beta_start = 0.0001, beta_end = 0.02):\n",
" \"\"\"\n",
" linar schedule from the original DDPM paper https://arxiv.org/abs/2006.11239\n",
" \"\"\"\n",
" return torch.linspace(beta_start, beta_end, timesteps)\n",
"\n",
"\n",
"def cosine_beta_schedule(timesteps, s=0.008):\n",
" \"\"\"\n",
" cosine schedule as proposed in https://arxiv.org/abs/2102.09672\n",
" \"\"\"\n",
" steps = timesteps + 1\n",
" x = torch.linspace(0, timesteps, steps)\n",
" alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * torch.pi * 0.5) ** 2\n",
" alphas_cumprod = alphas_cumprod / alphas_cumprod[0]\n",
" betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])\n",
" return torch.clip(betas, 0.0001, 0.9999)\n"
]
},
{
"cell_type": "markdown",
"id": "e18d1b38",
"metadata": {},
"source": [
"### Constants calculation\n",
"We will now create a function to calculate every constants we need for our Diffusion Model. <br/>\n",
"Constants:\n",
"- $ \\beta_t $: betas\n",
"- $ \\sqrt{\\frac{1}{\\alpha_t}} $: sqrt_recip_alphas\n",
"- $ \\sqrt{\\bar{\\alpha}_t} $: sqrt_alphas_cumprod\n",
"- $ \\sqrt{1-\\bar{\\alpha}_t} $: sqrt_one_minus_alphas_cumprod\n",
"- $ \\tilde{\\beta}_t = \\beta_t\\frac{1-\\bar{\\alpha}_{t-1}}{1-\\bar{\\alpha}_t} $: posterior_variance"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "84251513",
"metadata": {},
"outputs": [],
"source": [
"# Function to get alphas and betas\n",
"def get_alph_bet(timesteps, schedule=cosine_beta_schedule):\n",
" \n",
" # define beta\n",
" betas = schedule(timesteps)\n",
"\n",
" # define alphas \n",
" alphas = 1. - betas\n",
" alphas_cumprod = torch.cumprod(alphas, axis=0) # cumulative product of alpha\n",
" alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0) # corresponding to the prev const\n",
" sqrt_recip_alphas = torch.sqrt(1.0 / alphas)\n",
"\n",
" # calculations for diffusion q(x_t | x_{t-1}) and others\n",
" sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)\n",
" sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)\n",
"\n",
" # calculations for posterior q(x_{t-1} | x_t, x_0)\n",
" posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)\n",
" \n",
" const_dict = {\n",
" 'betas': betas,\n",
" 'sqrt_recip_alphas': sqrt_recip_alphas,\n",
" 'sqrt_alphas_cumprod': sqrt_alphas_cumprod,\n",
" 'sqrt_one_minus_alphas_cumprod': sqrt_one_minus_alphas_cumprod,\n",
" 'posterior_variance': posterior_variance\n",
" }\n",
" \n",
" return const_dict"
]
},
{
"cell_type": "markdown",
"id": "d5658d8e",
"metadata": {},
"source": [
"### Difference between Linear and Cosine schedule\n",
"We can check the differences between the constants when we change the parameters:"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7bfdf98c",
"metadata": {},
"outputs": [],
"source": [
"T = 1000\n",
"const_linear_dict = get_alph_bet(T, schedule=linear_beta_schedule)\n",
"const_cosine_dict = get_alph_bet(T, schedule=cosine_beta_schedule)\n",
"\n",
"plt.plot(np.arange(T), const_linear_dict['sqrt_alphas_cumprod'], color='r', label='linear')\n",
"plt.plot(np.arange(T), const_cosine_dict['sqrt_alphas_cumprod'], color='g', label='cosine')\n",
" \n",
"# Naming the x-axis, y-axis and the whole graph\n",
"plt.xlabel(\"Step\")\n",
"plt.ylabel(\"alpha_bar\")\n",
"plt.title(\"Linear and Cosine schedules\")\n",
" \n",
"# Adding legend, which helps us recognize the curve according to it's color\n",
"plt.legend()\n",
" \n",
"# To load the display window\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"id": "b1537984",
"metadata": {},
"source": [
"### Definition of $ q(x_t|x_0) $"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "cb10e05b",
"metadata": {},
"outputs": [],
"source": [
"# extract the values needed for time t\n",
"def extract(constants, batch_t, x_shape):\n",
" diffusion_batch_size = batch_t.shape[0]\n",
" \n",
" # get a list of the appropriate constants of each timesteps\n",
" out = constants.gather(-1, batch_t.cpu()) \n",
" \n",
" return out.reshape(diffusion_batch_size, *((1,) * (len(x_shape) - 1))).to(batch_t.device)\n"
]
},
{
"cell_type": "markdown",
"id": "2f5991bd",
"metadata": {},
"source": [
"Now that we have every constants that we need, we can create a function that will add noise to an image following the forward diffusion process. This function (q_sample) corresponds to $ q(x_t|x_0) $:\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "28645450",
"metadata": {},
"outputs": [],
"source": [
"# forward diffusion (using the nice property)\n",
"def q_sample(constants_dict, batch_x0, batch_t, noise=None):\n",
" if noise is None:\n",
" noise = torch.randn_like(batch_x0)\n",
"\n",
" sqrt_alphas_cumprod_t = extract(constants_dict['sqrt_alphas_cumprod'], batch_t, batch_x0.shape)\n",
" sqrt_one_minus_alphas_cumprod_t = extract(\n",
" constants_dict['sqrt_one_minus_alphas_cumprod'], batch_t, batch_x0.shape\n",
" )\n",
"\n",
" return sqrt_alphas_cumprod_t * batch_x0 + sqrt_one_minus_alphas_cumprod_t * noise"
]
},
{
"cell_type": "markdown",
"id": "dcc05f40",
"metadata": {},
"source": [
"We can now visualize how the forward diffusion process adds noise gradually the image according to its parameters:"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7ed20740",
"metadata": {},
"outputs": [],
"source": [
"T = 1000\n",
"const_linear_dict = get_alph_bet(T, schedule=linear_beta_schedule)\n",
"const_cosine_dict = get_alph_bet(T, schedule=cosine_beta_schedule)\n",
"\n",
"batch_t = torch.arange(batch_size)*(T//batch_size) # get a range of timesteps from 0 to T\n",
"print(f\"timesteps: {batch_t}\")\n",
"noisy_batch_linear = q_sample(const_linear_dict, batch_image, batch_t, noise=None)\n",
"noisy_batch_cosine = q_sample(const_cosine_dict, batch_image, batch_t, noise=None)\n",
"\n",
"print(\"Original images:\")\n",
"show_images(batch_image[:])\n",
"\n",
"print(\"Noised images with linear shedule:\")\n",
"show_images(noisy_batch_linear[:])\n",
"\n",
"print(\"Noised images with cosine shedule:\")\n",
"show_images(noisy_batch_cosine[:])"
]
},
{
"cell_type": "markdown",
"id": "565d3c80",
"metadata": {},
"source": [
"## Reverse Diffusion Process"
]
},
{
"cell_type": "markdown",
"id": "251808b0",
"metadata": {},
"source": [
"### Model definition\n",
"The reverse diffusion process is made by a deep learning model. We choosed a Unet model with attention. The model is optimized following some papers like [ConvNeXt](https://arxiv.org/pdf/2201.03545.pdf). You can inspect the model in the model.py file."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "29f00028",
"metadata": {},
"outputs": [],
"source": [
"from model import Unet\n",
"\n",
"model = Unet( \n",
" dim=28,\n",
" init_dim=None,\n",
" out_dim=None,\n",
" dim_mults=(1, 2, 4),\n",
" channels=1,\n",
" with_time_emb=True,\n",
" convnext_mult=2,\n",
")"
]
},
{
"cell_type": "markdown",
"id": "0aaf936c",
"metadata": {},
"source": [
"### Definition of $ p_{\\theta}(x_{t-1}|x_t) $\n",
"Now we need a function to retrieve $x_{t-1}$ from $x_t$ and the predicted $z_t$. It corresponds to the reverse diffusion kernel:\n",
"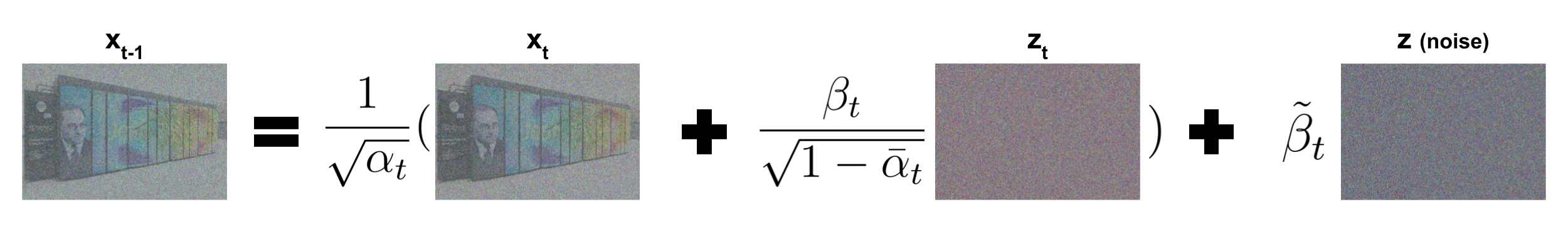"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "00443d8e",
"metadata": {},
"outputs": [],
"source": [
"@torch.no_grad()\n",
"def p_sample(constants_dict, batch_xt, predicted_noise, batch_t):\n",
" # We first get every constants needed and send them in right device\n",
" betas_t = extract(constants_dict['betas'], batch_t, batch_xt.shape).to(batch_xt.device)\n",
" sqrt_one_minus_alphas_cumprod_t = extract(\n",
" constants_dict['sqrt_one_minus_alphas_cumprod'], batch_t, batch_xt.shape\n",
" ).to(batch_xt.device)\n",
" sqrt_recip_alphas_t = extract(\n",
" constants_dict['sqrt_recip_alphas'], batch_t, batch_xt.shape\n",
" ).to(batch_xt.device)\n",
" \n",
" # Equation 11 in the ddpm paper\n",
" # Use predicted noise to predict the mean (mu theta)\n",
" model_mean = sqrt_recip_alphas_t * (\n",
" batch_xt - betas_t * predicted_noise / sqrt_one_minus_alphas_cumprod_t\n",
" )\n",
" \n",
" # We have to be careful to not add noise if we want to predict the final image\n",
" predicted_image = torch.zeros(batch_xt.shape).to(batch_xt.device)\n",
" t_zero_index = (batch_t == torch.zeros(batch_t.shape).to(batch_xt.device))\n",
" \n",
" # Algorithm 2 line 4, we add noise when timestep is not 1:\n",
" posterior_variance_t = extract(constants_dict['posterior_variance'], batch_t, batch_xt.shape)\n",
" noise = torch.randn_like(batch_xt) # create noise, same shape as batch_x\n",
" predicted_image[~t_zero_index] = model_mean[~t_zero_index] + (\n",
" torch.sqrt(posterior_variance_t[~t_zero_index]) * noise[~t_zero_index]\n",
" ) \n",
" \n",
" # If t=1 we don't add noise to mu\n",
" predicted_image[t_zero_index] = model_mean[t_zero_index]\n",
" \n",
" return predicted_image"
]
},
{
"cell_type": "markdown",
"id": "c6e13aa1",
"metadata": {},
"source": [
"## Sampling "
]
},
{
"cell_type": "markdown",
"id": "459df8a2",
"metadata": {},
"source": [
"We will now create the sampling function. Given trained model, it should generate all the images we want."
]
},
{
"cell_type": "markdown",
"id": "1e3cdf15",
"metadata": {},
"source": [
"With the reverse diffusion process and a trained model, we can now make the sampling function corresponding to this algorithm:\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "710ef636",
"metadata": {},
"outputs": [],
"source": [
"# Algorithm 2 (including returning all images)\n",
"@torch.no_grad()\n",
"def sampling(model, shape, T, constants_dict):\n",
" b = shape[0]\n",
" # start from pure noise (for each example in the batch)\n",
" batch_xt = torch.randn(shape, device=DEVICE)\n",
" \n",
" batch_t = torch.ones(shape[0]) * T # create a vector with batch-size time the timestep\n",
" batch_t = batch_t.type(torch.int64).to(DEVICE)\n",
" \n",
" imgs = []\n",
"\n",
" for t in tqdm(reversed(range(0, T)), desc='sampling loop time step', total=T):\n",
" batch_t -= 1\n",
" predicted_noise = model(batch_xt, batch_t)\n",
" \n",
" batch_xt = p_sample(constants_dict, batch_xt, predicted_noise, batch_t)\n",
" \n",
" imgs.append(batch_xt.cpu())\n",
" \n",
" return imgs"
]
},
{
"cell_type": "markdown",
"id": "df50675e",
"metadata": {},
"source": [
"## Training\n",
"We will instantiate every objects needed with fixed parameters here. We can try different hyperparameters by coming back here and changing the parameters."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a3884522",
"metadata": {},
"outputs": [],
"source": [
"# Dataset parameters\n",
"batch_size = 64\n",
"data_path = \"/gpfsdswork/dataset/HuggingFace/fashion_mnist/fashion_mnist/\"\n",
"# data_path = \"fashion_mnist\" # If you're not using Jean Zay\n",
"train_dataloader, channels, image_size, len_dataloader = get_dataset(data_path, batch_size)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b6b4a2bd",
"metadata": {},
"outputs": [],
"source": [
"constants_dict = get_alph_bet(T, schedule=linear_beta_schedule)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ba387427",
"metadata": {},
"outputs": [],
"source": [
"epochs = 3\n",
"T = 1000 # = T"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "31933494",
"metadata": {},
"outputs": [],
"source": [
"model = Unet( \n",
" dim=image_size,\n",
" init_dim=None,\n",
" out_dim=None,\n",
" dim_mults=(1, 2, 4),\n",
" channels=channels,\n",
" with_time_emb=True,\n",
" convnext_mult=2,\n",
").to(DEVICE)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "92fb2a17",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"criterion = nn.SmoothL1Loss()\n",
"optimizer = Adam(model.parameters(), lr=1e-4)"
]
},
{
"cell_type": "markdown",
"id": "f059d28f",
"metadata": {},
"source": [
"### Training loop\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4bab979d",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"for epoch in range(epochs):\n",
" loop = tqdm(train_dataloader, desc=f\"Epoch {epoch+1}/{epochs}\")\n",
" for batch in loop:\n",
" optimizer.zero_grad()\n",
"\n",
" batch_size_iter = batch[\"pixel_values\"].shape[0]\n",
" batch_image = batch[\"pixel_values\"].to(DEVICE)\n",
"\n",
" # Algorithm 1 line 3: sample t uniformally for every example in the batch\n",
" batch_t = torch.randint(0, T, (batch_size_iter,), device=DEVICE).long()\n",
" \n",
" noise = torch.randn_like(batch_image)\n",
" \n",
" x_noisy = q_sample(constants_dict, batch_image, batch_t, noise=noise)\n",
" predicted_noise = model(x_noisy, batch_t)\n",
" \n",
" loss = criterion(noise, predicted_noise)\n",
"\n",
" loop.set_postfix(loss=loss.item())\n",
"\n",
" loss.backward()\n",
" optimizer.step()\n",
"\n",
" \n",
"print(\"check generation:\") \n",
"list_gen_imgs = sampling(model, (batch_size, channels, image_size, image_size), T, constants_dict)\n",
"show_images(list_gen_imgs[-1])\n",
" "
]
},
{
"cell_type": "markdown",
"id": "2489e819",
"metadata": {},
"source": [
"## View of the diffusion process"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "09ce451d",
"metadata": {},
"outputs": [],
"source": [
"def make_gif(frame_list):\n",
" to_pil = ToPILImage()\n",
" frames = [to_pil(make_grid(normalize_im(tens_im))) for tens_im in frame_list]\n",
" frame_one = frames[0]\n",
" frame_one.save(\"sampling.gif.png\", format=\"GIF\", append_images=frames[::5], save_all=True, duration=10, loop=0)\n",
" \n",
" return IPython.display.Image(filename=\"./sampling.gif.png\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4f665ac3",
"metadata": {},
"outputs": [],
"source": [
"make_gif(list_gen_imgs)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "bfa40b6b",
"metadata": {},
"source": [
"---\n",
"<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "pytorch-gpu-1.13.0_py3.10.8",
"language": "python",
"name": "module-conda-env-pytorch-gpu-1.13.0_py3.10.8"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.8"
}
},
"nbformat": 4,
"nbformat_minor": 5
}