diff --git a/DCGAN-PyTorch/01-DCGAN-PL.ipynb b/DCGAN-PyTorch/01-DCGAN-PL.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..af0e5cc8d7ec3af234d193ce0c1ef3becf84bb2e
--- /dev/null
+++ b/DCGAN-PyTorch/01-DCGAN-PL.ipynb
@@ -0,0 +1,462 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
+ "\n",
+ "# <!-- TITLE --> [SHEEP3] - A DCGAN to Draw a Sheep, with Pytorch Lightning\n",
+ "<!-- DESC --> Episode 1 : Draw me a sheep, revisited with a DCGAN, writing in Pytorch Lightning\n",
+ "<!-- AUTHOR : Jean-Luc Parouty (CNRS/SIMaP) -->\n",
+ "\n",
+ "## Objectives :\n",
+ " - Build and train a DCGAN model with the Quick Draw dataset\n",
+ " - Understanding DCGAN\n",
+ "\n",
+ "The [Quick draw dataset](https://quickdraw.withgoogle.com/data) contains about 50.000.000 drawings, made by real people... \n",
+ "We are using a subset of 117.555 of Sheep drawings \n",
+ "To get the dataset : [https://github.com/googlecreativelab/quickdraw-dataset](https://github.com/googlecreativelab/quickdraw-dataset) \n",
+ "Datasets in numpy bitmap file : [https://console.cloud.google.com/storage/quickdraw_dataset/full/numpy_bitmap](https://console.cloud.google.com/storage/quickdraw_dataset/full/numpy_bitmap) \n",
+ "Sheep dataset : [https://storage.googleapis.com/quickdraw_dataset/full/numpy_bitmap/sheep.npy](https://storage.googleapis.com/quickdraw_dataset/full/numpy_bitmap/sheep.npy) (94.3 Mo)\n",
+ "\n",
+ "\n",
+ "## What we're going to do :\n",
+ "\n",
+ " - Have a look to the dataset\n",
+ " - Defining a GAN model\n",
+ " - Build the model\n",
+ " - Train it\n",
+ " - Have a look of the results"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Step 1 - Init and parameters\n",
+ "#### Python init"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import sys\n",
+ "import shutil\n",
+ "\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.nn.functional as F\n",
+ "import torchvision\n",
+ "import torchvision.transforms as transforms\n",
+ "from lightning import LightningDataModule, LightningModule, Trainer\n",
+ "from lightning.pytorch.callbacks.progress.tqdm_progress import TQDMProgressBar\n",
+ "from lightning.pytorch.callbacks.progress.base import ProgressBarBase\n",
+ "from lightning.pytorch.callbacks import ModelCheckpoint\n",
+ "from lightning.pytorch.loggers.tensorboard import TensorBoardLogger\n",
+ "\n",
+ "from tqdm import tqdm\n",
+ "from torch.utils.data import DataLoader\n",
+ "\n",
+ "import fidle\n",
+ "\n",
+ "from modules.SmartProgressBar import SmartProgressBar\n",
+ "from modules.QuickDrawDataModule import QuickDrawDataModule\n",
+ "\n",
+ "from modules.GAN import GAN\n",
+ "from modules.WGANGP import WGANGP\n",
+ "from modules.Generators import *\n",
+ "from modules.Discriminators import *\n",
+ "\n",
+ "# Init Fidle environment\n",
+ "run_id, run_dir, datasets_dir = fidle.init('SHEEP3')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Few parameters"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "latent_dim = 128\n",
+ "\n",
+ "gan_class = 'WGANGP'\n",
+ "generator_class = 'Generator_2'\n",
+ "discriminator_class = 'Discriminator_3' \n",
+ " \n",
+ "scale = 0.001\n",
+ "epochs = 3\n",
+ "lr = 0.0001\n",
+ "b1 = 0.5\n",
+ "b2 = 0.999\n",
+ "batch_size = 32\n",
+ "num_img = 48\n",
+ "fit_verbosity = 2\n",
+ " \n",
+ "dataset_file = datasets_dir+'/QuickDraw/origine/sheep.npy' \n",
+ "data_shape = (28,28,1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Cleaning"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# You can comment these lines to keep each run...\n",
+ "shutil.rmtree(f'{run_dir}/figs', ignore_errors=True)\n",
+ "shutil.rmtree(f'{run_dir}/models', ignore_errors=True)\n",
+ "shutil.rmtree(f'{run_dir}/tb_logs', ignore_errors=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Step 2 - Get some nice data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Get a Nice DataModule\n",
+ "Our DataModule is defined in [./modules/QuickDrawDataModule.py](./modules/QuickDrawDataModule.py) \n",
+ "This is a [LightningDataModule](https://pytorch-lightning.readthedocs.io/en/stable/data/datamodule.html)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "dm = QuickDrawDataModule(dataset_file, scale, batch_size, num_workers=8)\n",
+ "dm.setup()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Have a look"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dl = dm.train_dataloader()\n",
+ "batch_data = next(iter(dl))\n",
+ "\n",
+ "fidle.scrawler.images( batch_data.reshape(-1,28,28), indices=range(batch_size), columns=12, x_size=1, y_size=1, \n",
+ " y_padding=0,spines_alpha=0, save_as='01-Sheeps')"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Step 3 - Get a nice GAN model\n",
+ "\n",
+ "Our Generators are defined in [./modules/Generators.py](./modules/Generators.py) \n",
+ "Our Discriminators are defined in [./modules/Discriminators.py](./modules/Discriminators.py) \n",
+ "\n",
+ "\n",
+ "Our GAN is defined in [./modules/GAN.py](./modules/GAN.py) \n",
+ "\n",
+ "#### Class loader"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_class(class_name):\n",
+ " module=sys.modules['__main__']\n",
+ " class_ = getattr(module, class_name)\n",
+ " return class_\n",
+ " \n",
+ "def get_instance(class_name, **args):\n",
+ " module=sys.modules['__main__']\n",
+ " class_ = getattr(module, class_name)\n",
+ " instance_ = class_(**args)\n",
+ " return instance_"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Basic test - Just to be sure it (could) works... ;-)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# ---- A little piece of black magic to instantiate a class from its name\n",
+ "#\n",
+ "def get_classByName(class_name, **args):\n",
+ " module=sys.modules['__main__']\n",
+ " class_ = getattr(module, class_name)\n",
+ " instance_ = class_(**args)\n",
+ " return instance_\n",
+ "\n",
+ "# ----Get it, and play with them\n",
+ "#\n",
+ "print('\\nInstantiation :\\n')\n",
+ "\n",
+ "Generator_ = get_class(generator_class)\n",
+ "Discriminator_ = get_class(discriminator_class)\n",
+ "\n",
+ "generator = Generator_( latent_dim=latent_dim, data_shape=data_shape)\n",
+ "discriminator = Discriminator_( latent_dim=latent_dim, data_shape=data_shape)\n",
+ "\n",
+ "print('\\nFew tests :\\n')\n",
+ "z = torch.randn(batch_size, latent_dim)\n",
+ "print('z size : ',z.size())\n",
+ "\n",
+ "fake_img = generator.forward(z)\n",
+ "print('fake_img : ', fake_img.size())\n",
+ "\n",
+ "p = discriminator.forward(fake_img)\n",
+ "print('pred fake : ', p.size())\n",
+ "\n",
+ "print('batch_data : ',batch_data.size())\n",
+ "\n",
+ "p = discriminator.forward(batch_data)\n",
+ "print('pred real : ', p.size())\n",
+ "\n",
+ "nimg = fake_img.detach().numpy()\n",
+ "fidle.scrawler.images( nimg.reshape(-1,28,28), indices=range(batch_size), columns=12, x_size=1, y_size=1, \n",
+ " y_padding=0,spines_alpha=0, save_as='01-Sheeps')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "print(fake_img.size())\n",
+ "print(batch_data.size())\n",
+ "e = torch.distributions.uniform.Uniform(0, 1).sample([32,1])\n",
+ "e = e[:None,None,None]\n",
+ "i = fake_img * e + (1-e)*batch_data\n",
+ "\n",
+ "\n",
+ "nimg = i.detach().numpy()\n",
+ "fidle.scrawler.images( nimg.reshape(-1,28,28), indices=range(batch_size), columns=12, x_size=1, y_size=1, \n",
+ " y_padding=0,spines_alpha=0, save_as='01-Sheeps')\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### GAN model\n",
+ "To simplify our code, the GAN class is defined separately in the module [./modules/GAN.py](./modules/GAN.py) \n",
+ "Passing the classe names for generator/discriminator by parameter allows to stay modular and to use the PL checkpoints."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "GAN_ = get_class(gan_class)\n",
+ "\n",
+ "gan = GAN_( data_shape = data_shape,\n",
+ " lr = lr,\n",
+ " b1 = b1,\n",
+ " b2 = b2,\n",
+ " batch_size = batch_size, \n",
+ " latent_dim = latent_dim, \n",
+ " generator_class = generator_class, \n",
+ " discriminator_class = discriminator_class)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Step 5 - Train it !\n",
+ "#### Instantiate Callbacks, Logger & co.\n",
+ "More about :\n",
+ "- [Checkpoints](https://pytorch-lightning.readthedocs.io/en/stable/common/checkpointing_basic.html)\n",
+ "- [modelCheckpoint](https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.callbacks.ModelCheckpoint.html#pytorch_lightning.callbacks.ModelCheckpoint)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "\n",
+ "# ---- for tensorboard logs\n",
+ "#\n",
+ "logger = TensorBoardLogger( save_dir = f'{run_dir}',\n",
+ " name = 'tb_logs' )\n",
+ "\n",
+ "log_dir = os.path.abspath(f'{run_dir}/tb_logs')\n",
+ "print('To access the logs with tensorboard, use this command line :')\n",
+ "print(f'tensorboard --logdir {log_dir}')\n",
+ "\n",
+ "# ---- To save checkpoints\n",
+ "#\n",
+ "callback_checkpoints = ModelCheckpoint( dirpath = f'{run_dir}/models', \n",
+ " filename = 'bestModel', \n",
+ " save_top_k = 1, \n",
+ " save_last = True,\n",
+ " every_n_epochs = 1, \n",
+ " monitor = \"g_loss\")\n",
+ "\n",
+ "# ---- To have a nive progress bar\n",
+ "#\n",
+ "callback_progressBar = SmartProgressBar(verbosity=2) # Usable evertywhere\n",
+ "# progress_bar = TQDMProgressBar(refresh_rate=1) # Usable in real jupyter lab (bug in vscode)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Train it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "\n",
+ "trainer = Trainer(\n",
+ " accelerator = \"auto\",\n",
+ " max_epochs = epochs,\n",
+ " callbacks = [callback_progressBar, callback_checkpoints],\n",
+ " log_every_n_steps = batch_size,\n",
+ " logger = logger\n",
+ ")\n",
+ "\n",
+ "trainer.fit(gan, dm)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Step 6 - Reload our best model\n",
+ "Note : "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "gan = WGANGP.load_from_checkpoint('./run/SHEEP3/models/bestModel.ckpt')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nb_images = 96\n",
+ "\n",
+ "z = torch.randn(nb_images, latent_dim)\n",
+ "print('z size : ',z.size())\n",
+ "\n",
+ "fake_img = gan.generator.forward(z)\n",
+ "print('fake_img : ', fake_img.size())\n",
+ "\n",
+ "nimg = fake_img.detach().numpy()\n",
+ "fidle.scrawler.images( nimg.reshape(-1,28,28), indices=range(nb_images), columns=12, x_size=1, y_size=1, \n",
+ " y_padding=0,spines_alpha=0, save_as='01-Sheeps')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fidle.end()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---\n",
+ "<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "fidle-env",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.2"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/DCGAN-PyTorch/modules/Discriminators.py b/DCGAN-PyTorch/modules/Discriminators.py
new file mode 100644
index 0000000000000000000000000000000000000000..bdbaa79c08332bfcdd6c6a6e8ad3a4cee62f02e9
--- /dev/null
+++ b/DCGAN-PyTorch/modules/Discriminators.py
@@ -0,0 +1,136 @@
+# ------------------------------------------------------------------
+# _____ _ _ _
+# | ___(_) __| | | ___
+# | |_ | |/ _` | |/ _ \
+# | _| | | (_| | | __/
+# |_| |_|\__,_|_|\___| GAN / Generators
+# ------------------------------------------------------------------
+# Formation Introduction au Deep Learning (FIDLE)
+# CNRS/SARI/DEVLOG MIAI/EFELIA 2023 - https://fidle.cnrs.fr
+# ------------------------------------------------------------------
+# by JL Parouty (feb 2023) - PyTorch Lightning example
+
+import numpy as np
+import torch.nn as nn
+
+class Discriminator_1(nn.Module):
+ '''
+ A basic DNN discriminator, usable with classic GAN
+ '''
+
+ def __init__(self, latent_dim=None, data_shape=None):
+
+ super().__init__()
+ self.img_shape = data_shape
+ print('init discriminator 1 : ',data_shape,' to sigmoid')
+
+ self.model = nn.Sequential(
+
+ nn.Flatten(),
+ nn.Linear(int(np.prod(data_shape)), 512),
+ nn.ReLU(),
+
+ nn.Linear(512, 256),
+ nn.ReLU(),
+
+ nn.Linear(256, 1),
+ nn.Sigmoid(),
+ )
+
+ def forward(self, img):
+ validity = self.model(img)
+
+ return validity
+
+
+
+
+class Discriminator_2(nn.Module):
+ '''
+ A more efficient discriminator,based on CNN, usable with classic GAN
+ '''
+
+ def __init__(self, latent_dim=None, data_shape=None):
+
+ super().__init__()
+ self.img_shape = data_shape
+ print('init discriminator 2 : ',data_shape,' to sigmoid')
+
+ self.model = nn.Sequential(
+
+ nn.Conv2d(1, 32, kernel_size = 3, stride = 2, padding = 1),
+ nn.ReLU(),
+ nn.BatchNorm2d(32),
+ nn.Dropout2d(0.25),
+
+ nn.Conv2d(32, 64, kernel_size = 3, stride = 1, padding = 1),
+ nn.ReLU(),
+ nn.BatchNorm2d(64),
+ nn.Dropout2d(0.25),
+
+ nn.Conv2d(64, 128, kernel_size = 3, stride = 1, padding = 1),
+ nn.ReLU(),
+ nn.BatchNorm2d(128),
+ nn.Dropout2d(0.25),
+
+ nn.Conv2d(128, 256, kernel_size = 3, stride = 2, padding = 1),
+ nn.ReLU(),
+ nn.BatchNorm2d(256),
+ nn.Dropout2d(0.25),
+
+ nn.Flatten(),
+ nn.Linear(12544, 1),
+ nn.Sigmoid(),
+ )
+
+ def forward(self, img):
+ img_nchw = img.permute(0, 3, 1, 2) # reformat from NHWC to NCHW
+ validity = self.model(img_nchw)
+
+ return validity
+
+
+
+class Discriminator_3(nn.Module):
+ '''
+ A CNN discriminator, usable with a WGANGP.
+ This discriminator has no sigmoid and returns a critical and not a probability
+ '''
+
+ def __init__(self, latent_dim=None, data_shape=None):
+
+ super().__init__()
+ self.img_shape = data_shape
+ print('init discriminator 2 : ',data_shape,' to sigmoid')
+
+ self.model = nn.Sequential(
+
+ nn.Conv2d(1, 32, kernel_size = 3, stride = 2, padding = 1),
+ nn.ReLU(),
+ nn.BatchNorm2d(32),
+ nn.Dropout2d(0.25),
+
+ nn.Conv2d(32, 64, kernel_size = 3, stride = 1, padding = 1),
+ nn.ReLU(),
+ nn.BatchNorm2d(64),
+ nn.Dropout2d(0.25),
+
+ nn.Conv2d(64, 128, kernel_size = 3, stride = 1, padding = 1),
+ nn.ReLU(),
+ nn.BatchNorm2d(128),
+ nn.Dropout2d(0.25),
+
+ nn.Conv2d(128, 256, kernel_size = 3, stride = 2, padding = 1),
+ nn.ReLU(),
+ nn.BatchNorm2d(256),
+ nn.Dropout2d(0.25),
+
+ nn.Flatten(),
+ nn.Linear(12544, 1),
+ )
+
+ def forward(self, img):
+ img_nchw = img.permute(0, 3, 1, 2) # reformat from NHWC to NCHW
+ validity = self.model(img_nchw)
+
+ return validity
\ No newline at end of file
diff --git a/DCGAN-PyTorch/modules/GAN.py b/DCGAN-PyTorch/modules/GAN.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf5a5697f5e259178411706c52decdef6f176eea
--- /dev/null
+++ b/DCGAN-PyTorch/modules/GAN.py
@@ -0,0 +1,182 @@
+
+# ------------------------------------------------------------------
+# _____ _ _ _
+# | ___(_) __| | | ___
+# | |_ | |/ _` | |/ _ \
+# | _| | | (_| | | __/
+# |_| |_|\__,_|_|\___| GAN / GAN LigthningModule
+# ------------------------------------------------------------------
+# Formation Introduction au Deep Learning (FIDLE)
+# CNRS/SARI/DEVLOG MIAI/EFELIA 2023 - https://fidle.cnrs.fr
+# ------------------------------------------------------------------
+# by JL Parouty (feb 2023) - PyTorch Lightning example
+
+
+import sys
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torchvision
+from lightning import LightningModule
+
+
+class GAN(LightningModule):
+
+ # -------------------------------------------------------------------------
+ # Init
+ # -------------------------------------------------------------------------
+ #
+ def __init__(
+ self,
+ data_shape = (None,None,None),
+ latent_dim = None,
+ lr = 0.0002,
+ b1 = 0.5,
+ b2 = 0.999,
+ batch_size = 64,
+ generator_class = None,
+ discriminator_class = None,
+ **kwargs,
+ ):
+ super().__init__()
+
+ print('\n---- GAN initialization --------------------------------------------')
+
+ # ---- Hyperparameters
+ #
+ # Enable Lightning to store all the provided arguments under the self.hparams attribute.
+ # These hyperparameters will also be stored within the model checkpoint.
+ #
+ self.save_hyperparameters()
+
+ print('Hyperarameters are :')
+ for name,value in self.hparams.items():
+ print(f'{name:24s} : {value}')
+
+ # ---- Generator/Discriminator instantiation
+ #
+ # self.generator = Generator(latent_dim=self.hparams.latent_dim, img_shape=data_shape)
+ # self.discriminator = Discriminator(img_shape=data_shape)
+
+ print('Submodels :')
+ module=sys.modules['__main__']
+ class_g = getattr(module, generator_class)
+ class_d = getattr(module, discriminator_class)
+ self.generator = class_g( latent_dim=latent_dim, data_shape=data_shape)
+ self.discriminator = class_d( latent_dim=latent_dim, data_shape=data_shape)
+
+ # ---- Validation and example data
+ #
+ self.validation_z = torch.randn(8, self.hparams.latent_dim)
+ self.example_input_array = torch.zeros(2, self.hparams.latent_dim)
+
+
+ def forward(self, z):
+ return self.generator(z)
+
+
+ def adversarial_loss(self, y_hat, y):
+ return F.binary_cross_entropy(y_hat, y)
+
+
+ def training_step(self, batch, batch_idx, optimizer_idx):
+ imgs = batch
+ batch_size = batch.size(0)
+
+ # ---- Get some latent space vectors
+ # We use type_as() to make sure we initialize z on the right device (GPU/CPU).
+ #
+ z = torch.randn(batch_size, self.hparams.latent_dim)
+ z = z.type_as(imgs)
+
+ # ---- Train generator
+ # Generator use optimizer #0
+ # We try to generate false images that could mislead the discriminator
+ #
+ if optimizer_idx == 0:
+
+ # Generate fake images
+ self.fake_imgs = self.generator.forward(z)
+
+ # Assemble labels that say all images are real, yes it's a lie ;-)
+ # put on GPU because we created this tensor inside training_loop
+ misleading_labels = torch.ones(batch_size, 1)
+ misleading_labels = misleading_labels.type_as(imgs)
+
+ # Adversarial loss is binary cross-entropy
+ g_loss = self.adversarial_loss(self.discriminator.forward(self.fake_imgs), misleading_labels)
+ self.log("g_loss", g_loss, prog_bar=True)
+ return g_loss
+
+ # ---- Train discriminator
+ # Discriminator use optimizer #1
+ # We try to make the difference between fake images and real ones
+ #
+ if optimizer_idx == 1:
+
+ # These images are reals
+ real_labels = torch.ones(batch_size, 1)
+ real_labels = real_labels.type_as(imgs)
+ pred_labels = self.discriminator.forward(imgs)
+
+ real_loss = self.adversarial_loss(pred_labels, real_labels)
+
+ # These images are fake
+ fake_imgs = self.generator.forward(z)
+ fake_labels = torch.zeros(batch_size, 1)
+ fake_labels = fake_labels.type_as(imgs)
+
+ fake_loss = self.adversarial_loss(self.discriminator(fake_imgs.detach()), fake_labels)
+
+ # Discriminator loss is the average
+ d_loss = (real_loss + fake_loss) / 2
+ self.log("d_loss", d_loss, prog_bar=True)
+ return d_loss
+
+
+ def configure_optimizers(self):
+
+ lr = self.hparams.lr
+ b1 = self.hparams.b1
+ b2 = self.hparams.b2
+
+ # With a GAN, we need 2 separate optimizer.
+ # opt_g to optimize the generator #0
+ # opt_d to optimize the discriminator #1
+ # opt_g = torch.optim.Adam(self.generator.parameters(), lr=lr, betas=(b1, b2))
+ # opt_d = torch.optim.Adam(self.discriminator.parameters(), lr=lr, betas=(b1, b2),)
+ opt_g = torch.optim.Adam(self.generator.parameters(), lr=lr)
+ opt_d = torch.optim.Adam(self.discriminator.parameters(), lr=lr)
+ return [opt_g, opt_d], []
+
+
+ def training_epoch_end(self, outputs):
+
+ # Get our validation latent vectors as z
+ # z = self.validation_z.type_as(self.generator.model[0].weight)
+
+ # ---- Log Graph
+ #
+ if(self.current_epoch==1):
+ sampleImg=torch.rand((1,28,28,1))
+ sampleImg=sampleImg.type_as(self.generator.model[0].weight)
+ self.logger.experiment.add_graph(self.discriminator,sampleImg)
+
+ # ---- Log d_loss/epoch
+ #
+ g_loss, d_loss = 0,0
+ for metrics in outputs:
+ g_loss+=float( metrics[0]['loss'] )
+ d_loss+=float( metrics[1]['loss'] )
+ g_loss, d_loss = g_loss/len(outputs), d_loss/len(outputs)
+ self.logger.experiment.add_scalar("g_loss/epochs",g_loss, self.current_epoch)
+ self.logger.experiment.add_scalar("d_loss/epochs",d_loss, self.current_epoch)
+
+ # ---- Log some of these images
+ #
+ z = torch.randn(self.hparams.batch_size, self.hparams.latent_dim)
+ z = z.type_as(self.generator.model[0].weight)
+ sample_imgs = self.generator(z)
+ sample_imgs = sample_imgs.permute(0, 3, 1, 2) # from NHWC to NCHW
+ grid = torchvision.utils.make_grid(tensor=sample_imgs, nrow=12, )
+ self.logger.experiment.add_image(f"Generated images", grid,self.current_epoch)
diff --git a/DCGAN-PyTorch/modules/Generators.py b/DCGAN-PyTorch/modules/Generators.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b104d579469f51dfda08b1332c9b100b6fddaa4
--- /dev/null
+++ b/DCGAN-PyTorch/modules/Generators.py
@@ -0,0 +1,94 @@
+
+# ------------------------------------------------------------------
+# _____ _ _ _
+# | ___(_) __| | | ___
+# | |_ | |/ _` | |/ _ \
+# | _| | | (_| | | __/
+# |_| |_|\__,_|_|\___| GAN / Generators
+# ------------------------------------------------------------------
+# Formation Introduction au Deep Learning (FIDLE)
+# CNRS/SARI/DEVLOG MIAI/EFELIA 2023 - https://fidle.cnrs.fr
+# ------------------------------------------------------------------
+# by JL Parouty (feb 2023) - PyTorch Lightning example
+
+
+import numpy as np
+import torch.nn as nn
+
+
+class Generator_1(nn.Module):
+
+ def __init__(self, latent_dim=None, data_shape=None):
+ super().__init__()
+ self.latent_dim = latent_dim
+ self.img_shape = data_shape
+ print('init generator 1 : ',latent_dim,' to ',data_shape)
+
+ self.model = nn.Sequential(
+
+ nn.Linear(latent_dim, 128),
+ nn.ReLU(),
+
+ nn.Linear(128,256),
+ nn.BatchNorm1d(256, 0.8),
+ nn.ReLU(),
+
+ nn.Linear(256, 512),
+ nn.BatchNorm1d(512, 0.8),
+ nn.ReLU(),
+
+ nn.Linear(512, 1024),
+ nn.BatchNorm1d(1024, 0.8),
+ nn.ReLU(),
+
+ nn.Linear(1024, int(np.prod(data_shape))),
+ nn.Sigmoid()
+
+ )
+
+
+ def forward(self, z):
+ img = self.model(z)
+ img = img.view(img.size(0), *self.img_shape)
+ return img
+
+
+
+class Generator_2(nn.Module):
+
+ def __init__(self, latent_dim=None, data_shape=None):
+ super().__init__()
+ self.latent_dim = latent_dim
+ self.img_shape = data_shape
+ print('init generator 2 : ',latent_dim,' to ',data_shape)
+
+ self.model = nn.Sequential(
+
+ nn.Linear(latent_dim, 7*7*64),
+ nn.Unflatten(1, (64,7,7)),
+
+ # nn.UpsamplingNearest2d( scale_factor=2 ),
+ nn.UpsamplingBilinear2d( scale_factor=2 ),
+ nn.Conv2d( 64,128, (3,3), stride=(1,1), padding=(1,1) ),
+ nn.ReLU(),
+ nn.BatchNorm2d(128),
+
+ # nn.UpsamplingNearest2d( scale_factor=2 ),
+ nn.UpsamplingBilinear2d( scale_factor=2 ),
+ nn.Conv2d( 128,256, (3,3), stride=(1,1), padding=(1,1)),
+ nn.ReLU(),
+ nn.BatchNorm2d(256),
+
+ nn.Conv2d( 256,1, (5,5), stride=(1,1), padding=(2,2)),
+ nn.Sigmoid()
+
+ )
+
+ def forward(self, z):
+ img_nchw = self.model(z)
+ img_nhwc = img_nchw.permute(0, 2, 3, 1) # reformat from NCHW to NHWC
+ # img = img.view(img.size(0), *self.img_shape) # reformat from NCHW to NHWC
+ return img_nhwc
+
+
+
diff --git a/DCGAN-PyTorch/modules/QuickDrawDataModule.py b/DCGAN-PyTorch/modules/QuickDrawDataModule.py
new file mode 100644
index 0000000000000000000000000000000000000000..34a4ecfba7e5d123a833e5a6e58d14e4d4903d53
--- /dev/null
+++ b/DCGAN-PyTorch/modules/QuickDrawDataModule.py
@@ -0,0 +1,71 @@
+
+# ------------------------------------------------------------------
+# _____ _ _ _
+# | ___(_) __| | | ___
+# | |_ | |/ _` | |/ _ \
+# | _| | | (_| | | __/
+# |_| |_|\__,_|_|\___| GAN / QuickDrawDataModule
+# ------------------------------------------------------------------
+# Formation Introduction au Deep Learning (FIDLE)
+# CNRS/SARI/DEVLOG MIAI/EFELIA 2023 - https://fidle.cnrs.fr
+# ------------------------------------------------------------------
+# by JL Parouty (feb 2023) - PyTorch Lightning example
+
+
+import numpy as np
+import torch
+from lightning import LightningDataModule
+from torch.utils.data import DataLoader
+
+
+class QuickDrawDataModule(LightningDataModule):
+
+
+ def __init__( self, dataset_file='./sheep.npy', scale=1., batch_size=64, num_workers=4 ):
+
+ super().__init__()
+
+ print('\n---- QuickDrawDataModule initialization ----------------------------')
+ print(f'with : scale={scale} batch size={batch_size}')
+
+ self.scale = scale
+ self.dataset_file = dataset_file
+ self.batch_size = batch_size
+ self.num_workers = num_workers
+
+ self.dims = (28, 28, 1)
+ self.num_classes = 10
+
+
+
+ def prepare_data(self):
+ pass
+
+
+ def setup(self, stage=None):
+ print('\nDataModule Setup :')
+ # Load dataset
+ # Called at the beginning of each stage (train,val,test)
+ # Here, whatever the stage value, we'll have only one set.
+ data = np.load(self.dataset_file)
+ print('Original dataset shape : ',data.shape)
+
+ # Rescale
+ n=int(self.scale*len(data))
+ data = data[:n]
+ print('Rescaled dataset shape : ',data.shape)
+
+ # Normalize, reshape and shuffle
+ data = data/255
+ data = data.reshape(-1,28,28,1)
+ data = torch.from_numpy(data).float()
+ print('Final dataset shape : ',data.shape)
+
+ print('Dataset loaded and ready.')
+ self.data_train = data
+
+
+ def train_dataloader(self):
+ # Note : Numpy ndarray is Dataset compliant
+ # Have map-style interface. See https://pytorch.org/docs/stable/data.html
+ return DataLoader( self.data_train, batch_size=self.batch_size, num_workers=self.num_workers )
\ No newline at end of file
diff --git a/DCGAN-PyTorch/modules/SmartProgressBar.py b/DCGAN-PyTorch/modules/SmartProgressBar.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ebe192d0d9732da08125fa0503b2b6f7a59cf02
--- /dev/null
+++ b/DCGAN-PyTorch/modules/SmartProgressBar.py
@@ -0,0 +1,70 @@
+
+# ------------------------------------------------------------------
+# _____ _ _ _
+# | ___(_) __| | | ___
+# | |_ | |/ _` | |/ _ \
+# | _| | | (_| | | __/
+# |_| |_|\__,_|_|\___| GAN / SmartProgressBar
+# ------------------------------------------------------------------
+# Formation Introduction au Deep Learning (FIDLE)
+# CNRS/SARI/DEVLOG MIAI/EFELIA 2023 - https://fidle.cnrs.fr
+# ------------------------------------------------------------------
+# by JL Parouty (feb 2023) - PyTorch Lightning example
+
+from lightning.pytorch.callbacks.progress.base import ProgressBarBase
+from tqdm import tqdm
+import sys
+
+class SmartProgressBar(ProgressBarBase):
+
+ def __init__(self, verbosity=2):
+ super().__init__()
+ self.verbosity = verbosity
+
+ def disable(self):
+ self.enable = False
+
+
+ def setup(self, trainer, pl_module, stage):
+ super().setup(trainer, pl_module, stage)
+ self.stage = stage
+
+
+ def on_train_epoch_start(self, trainer, pl_module):
+ super().on_train_epoch_start(trainer, pl_module)
+ if not self.enable : return
+
+ if self.verbosity==2:
+ self.progress=tqdm( total=trainer.num_training_batches,
+ desc=f'{self.stage} {trainer.current_epoch+1}/{trainer.max_epochs}',
+ ncols=100, ascii= " >",
+ bar_format='{l_bar}{bar}| [{elapsed}] {postfix}')
+
+
+
+ def on_train_epoch_end(self, trainer, pl_module):
+ super().on_train_epoch_end(trainer, pl_module)
+
+ if not self.enable : return
+
+ if self.verbosity==2:
+ self.progress.close()
+
+ if self.verbosity==1:
+ print(f'Train {trainer.current_epoch+1}/{trainer.max_epochs} Done.')
+
+
+ def on_train_batch_end(self, trainer, pl_module, outputs, batch, batch_idx):
+ super().on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
+
+ if not self.enable : return
+
+ if self.verbosity==2:
+ metrics = {}
+ for name,value in trainer.logged_metrics.items():
+ metrics[name]=f'{float( trainer.logged_metrics[name] ):3.3f}'
+ self.progress.set_postfix(metrics)
+ self.progress.update(1)
+
+
+progress_bar = SmartProgressBar(verbosity=2)
diff --git a/DCGAN-PyTorch/modules/WGANGP.py b/DCGAN-PyTorch/modules/WGANGP.py
new file mode 100644
index 0000000000000000000000000000000000000000..030740b562d2bbac62f17fc671e530fc9383ed7d
--- /dev/null
+++ b/DCGAN-PyTorch/modules/WGANGP.py
@@ -0,0 +1,229 @@
+
+# ------------------------------------------------------------------
+# _____ _ _ _
+# | ___(_) __| | | ___
+# | |_ | |/ _` | |/ _ \
+# | _| | | (_| | | __/
+# |_| |_|\__,_|_|\___| GAN / GAN LigthningModule
+# ------------------------------------------------------------------
+# Formation Introduction au Deep Learning (FIDLE)
+# CNRS/SARI/DEVLOG MIAI/EFELIA 2023 - https://fidle.cnrs.fr
+# ------------------------------------------------------------------
+# by JL Parouty (feb 2023) - PyTorch Lightning example
+
+
+import sys
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torchvision
+from lightning import LightningModule
+
+
+class WGANGP(LightningModule):
+
+ # -------------------------------------------------------------------------
+ # Init
+ # -------------------------------------------------------------------------
+ #
+ def __init__(
+ self,
+ data_shape = (None,None,None),
+ latent_dim = None,
+ lr = 0.0002,
+ b1 = 0.5,
+ b2 = 0.999,
+ batch_size = 64,
+ lambda_gp = 10,
+ generator_class = None,
+ discriminator_class = None,
+ **kwargs,
+ ):
+ super().__init__()
+
+ print('\n---- WGANGP initialization -----------------------------------------')
+
+ # ---- Hyperparameters
+ #
+ # Enable Lightning to store all the provided arguments under the self.hparams attribute.
+ # These hyperparameters will also be stored within the model checkpoint.
+ #
+ self.save_hyperparameters()
+
+ print('Hyperarameters are :')
+ for name,value in self.hparams.items():
+ print(f'{name:24s} : {value}')
+
+ # ---- Generator/Discriminator instantiation
+ #
+ # self.generator = Generator(latent_dim=self.hparams.latent_dim, img_shape=data_shape)
+ # self.discriminator = Discriminator(img_shape=data_shape)
+
+ print('Submodels :')
+ module=sys.modules['__main__']
+ class_g = getattr(module, generator_class)
+ class_d = getattr(module, discriminator_class)
+ self.generator = class_g( latent_dim=latent_dim, data_shape=data_shape)
+ self.discriminator = class_d( latent_dim=latent_dim, data_shape=data_shape)
+
+ # ---- Validation and example data
+ #
+ self.validation_z = torch.randn(8, self.hparams.latent_dim)
+ self.example_input_array = torch.zeros(2, self.hparams.latent_dim)
+
+
+ def forward(self, z):
+ return self.generator(z)
+
+
+ def adversarial_loss(self, y_hat, y):
+ return F.binary_cross_entropy(y_hat, y)
+
+
+
+# ------------------------------------------------------------------------------------ TO DO -------------------
+
+ # see : # from : https://github.com/rosshemsley/gander/blob/main/gander/models/gan.py
+
+ def gradient_penalty(self, real_images, fake_images):
+
+ batch_size = real_images.size(0)
+
+ # ---- Create interpolate images
+ #
+ # Get a random vector : size=([batch_size])
+ epsilon = torch.distributions.uniform.Uniform(0, 1).sample([batch_size])
+ # Add dimensions to match images batch : size=([batch_size,1,1,1])
+ epsilon = epsilon[:, None, None, None]
+ # Put epsilon a the right place
+ epsilon = epsilon.type_as(real_images)
+ # Do interpolation
+ interpolates = epsilon * fake_images + ((1 - epsilon) * real_images)
+
+ # ---- Use autograd to compute gradient
+ #
+ # The key to making this work is including `create_graph`, this means that the computations
+ # in this penalty will be added to the computation graph for the loss function, so that the
+ # second partial derivatives will be correctly computed.
+ #
+ interpolates.requires_grad = True
+
+ pred_labels = self.discriminator.forward(interpolates)
+
+ gradients = torch.autograd.grad( inputs = interpolates,
+ outputs = pred_labels,
+ grad_outputs = torch.ones_like(pred_labels),
+ create_graph = True,
+ only_inputs = True )[0]
+
+ grad_flat = gradients.view(batch_size, -1)
+ grad_norm = torch.linalg.norm(grad_flat, dim=1)
+
+ grad_penalty = (grad_norm - 1) ** 2
+
+ return grad_penalty
+
+
+
+# ------------------------------------------------------------------------------------------------------------------
+
+
+ def training_step(self, batch, batch_idx, optimizer_idx):
+
+ real_imgs = batch
+ batch_size = batch.size(0)
+ lambda_gp = self.hparams.lambda_gp
+
+ # ---- Get some latent space vectors and fake images
+ # We use type_as() to make sure we initialize z on the right device (GPU/CPU).
+ #
+ z = torch.randn(batch_size, self.hparams.latent_dim)
+ z = z.type_as(real_imgs)
+
+ fake_imgs = self.generator.forward(z)
+
+ # ---- Train generator
+ # Generator use optimizer #0
+ # We try to generate false images that could have nive critics
+ #
+ if optimizer_idx == 0:
+
+ # Get critics
+ critics = self.discriminator.forward(fake_imgs)
+
+ # Loss
+ g_loss = -critics.mean()
+
+ # Log
+ self.log("g_loss", g_loss, prog_bar=True)
+
+ return g_loss
+
+ # ---- Train discriminator
+ # Discriminator use optimizer #1
+ # We try to make the difference between fake images and real ones
+ #
+ if optimizer_idx == 1:
+
+ # Get critics
+ critics_real = self.discriminator.forward(real_imgs)
+ critics_fake = self.discriminator.forward(fake_imgs)
+
+ # Get gradient penalty
+ grad_penalty = self.gradient_penalty(real_imgs, fake_imgs)
+
+ # Loss
+ d_loss = critics_fake.mean() - critics_real.mean() + lambda_gp*grad_penalty.mean()
+
+ # Log loss
+ self.log("d_loss", d_loss, prog_bar=True)
+
+ return d_loss
+
+
+ def configure_optimizers(self):
+
+ lr = self.hparams.lr
+ b1 = self.hparams.b1
+ b2 = self.hparams.b2
+
+ # With a GAN, we need 2 separate optimizer.
+ # opt_g to optimize the generator #0
+ # opt_d to optimize the discriminator #1
+ # opt_g = torch.optim.Adam(self.generator.parameters(), lr=lr, betas=(b1, b2))
+ # opt_d = torch.optim.Adam(self.discriminator.parameters(), lr=lr, betas=(b1, b2),)
+ opt_g = torch.optim.Adam(self.generator.parameters(), lr=lr)
+ opt_d = torch.optim.Adam(self.discriminator.parameters(), lr=lr)
+ return [opt_g, opt_d], []
+
+
+ def training_epoch_end(self, outputs):
+
+ # Get our validation latent vectors as z
+ # z = self.validation_z.type_as(self.generator.model[0].weight)
+
+ # ---- Log Graph
+ #
+ if(self.current_epoch==1):
+ sampleImg=torch.rand((1,28,28,1))
+ sampleImg=sampleImg.type_as(self.generator.model[0].weight)
+ self.logger.experiment.add_graph(self.discriminator,sampleImg)
+
+ # ---- Log d_loss/epoch
+ #
+ g_loss, d_loss = 0,0
+ for metrics in outputs:
+ g_loss+=float( metrics[0]['loss'] )
+ d_loss+=float( metrics[1]['loss'] )
+ g_loss, d_loss = g_loss/len(outputs), d_loss/len(outputs)
+ self.logger.experiment.add_scalar("g_loss/epochs",g_loss, self.current_epoch)
+ self.logger.experiment.add_scalar("d_loss/epochs",d_loss, self.current_epoch)
+
+ # ---- Log some of these images
+ #
+ z = torch.randn(self.hparams.batch_size, self.hparams.latent_dim)
+ z = z.type_as(self.generator.model[0].weight)
+ sample_imgs = self.generator(z)
+ sample_imgs = sample_imgs.permute(0, 3, 1, 2) # from NHWC to NCHW
+ grid = torchvision.utils.make_grid(tensor=sample_imgs, nrow=12, )
+ self.logger.experiment.add_image(f"Generated images", grid,self.current_epoch)
diff --git a/DDPM/01-ddpm.ipynb b/DDPM/01-ddpm.ipynb
new file mode 100755
index 0000000000000000000000000000000000000000..06a7936777604f8d5d5cc8132fbed8ebc27df4eb
--- /dev/null
+++ b/DDPM/01-ddpm.ipynb
@@ -0,0 +1,820 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "756b572d",
+ "metadata": {},
+ "source": [
+ "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
+ "\n",
+ "# <!-- TITLE --> [DDPM1] - Fashion MNIST Generation with DDPM\n",
+ "<!-- DESC --> Diffusion Model example, to generate Fashion MNIST images.\n",
+ "\n",
+ "<!-- AUTHOR : Hatim Bourfoune (CNRS/IDRIS), Maxime Song (CNRS/IDRIS) -->\n",
+ "\n",
+ "## Objectives :\n",
+ " - Understanding and implementing a **Diffusion Model** neurals network (DDPM)\n",
+ "\n",
+ "The calculation needs being important, it is preferable to use a very simple dataset such as MNIST to start with. \n",
+ "...MNIST with a small scale (need to adapt the code !) if you haven't a GPU ;-)\n",
+ "\n",
+ "\n",
+ "## Acknowledgements :\n",
+ "This notebook was heavily inspired by this [article](https://huggingface.co/blog/annotated-diffusion) and this [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/annotated_diffusion.ipynb#scrollTo=5153024b). "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "54a15542",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import math\n",
+ "from inspect import isfunction\n",
+ "from functools import partial\n",
+ "import random\n",
+ "import IPython\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "from tqdm.auto import tqdm\n",
+ "from einops import rearrange\n",
+ "\n",
+ "import torch\n",
+ "from torch import nn, einsum\n",
+ "import torch.nn.functional as F\n",
+ "from datasets import load_dataset, load_from_disk\n",
+ "\n",
+ "from torchvision import transforms\n",
+ "from torchvision.utils import make_grid\n",
+ "from torch.utils.data import DataLoader\n",
+ "import numpy as np\n",
+ "from PIL import Image\n",
+ "from torch.optim import Adam\n",
+ "\n",
+ "from torchvision.transforms import Compose, ToTensor, Lambda, ToPILImage, CenterCrop, Resize\n",
+ "import matplotlib.pyplot as plt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a854c28a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "DEVICE = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
+ "\n",
+ "# Reproductibility\n",
+ "torch.manual_seed(53)\n",
+ "random.seed(53)\n",
+ "np.random.seed(53)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e33f10db",
+ "metadata": {},
+ "source": [
+ "## Create dataset\n",
+ "We will use the library HuggingFace Datasets to get our Fashion MNIST. If you are using Jean Zay, the dataset is already downloaded in the DSDIR, so you can use the code as it is. If you are not using Jean Zay, you should use the function load_dataset (commented) instead of load_from_disk. It will automatically download the dataset if it is not downloaded already."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "918c0138",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dataset = load_dataset(\"fashion_mnist\") \n",
+ "dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cfe4d4f5",
+ "metadata": {},
+ "source": [
+ "As you can see the dataset is composed of two subparts: train and test. So the dataset is already split for us. We'll use the train part for now. <br/>\n",
+ "We can also see that the dataset as two features per sample: 'image' corresponding to the PIL version of the image and 'label' corresponding to the class of the image (shoe, shirt...). We can also see that there are 60 000 samples in our train dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2280400d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_dataset = dataset['train']\n",
+ "train_dataset[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7978ad3d",
+ "metadata": {},
+ "source": [
+ "Each sample of a HuggingFace dataset is a dictionary containing the data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d157e11",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image = train_dataset[0]['image']\n",
+ "image"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5dea3e5a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "image_array = np.asarray(image, dtype=np.uint8)\n",
+ "print(f\"shape of the image: {image_array.shape}\")\n",
+ "print(f\"min: {image_array.min()}, max: {image_array.max()}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f86937e9",
+ "metadata": {},
+ "source": [
+ "We will now create a function that get the Fashion MNIST dataset needed, apply all the transformations we want on it and encapsulate that dataset in a dataloader."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e646a7b1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# load hugging face dataset from the DSDIR\n",
+ "def get_dataset(data_path, batch_size, test = False):\n",
+ " \n",
+ " dataset = load_from_disk(data_path)\n",
+ " # dataset = load_dataset(data_path) # Use this one if you're not on Jean Zay\n",
+ "\n",
+ " # define image transformations (e.g. using torchvision)\n",
+ " transform = Compose([\n",
+ " transforms.RandomHorizontalFlip(), # Data augmentation\n",
+ " transforms.ToTensor(), # Transform PIL image into tensor of value between [0,1]\n",
+ " transforms.Lambda(lambda t: (t * 2) - 1) # Normalize values between [-1,1]\n",
+ " ])\n",
+ "\n",
+ " # define function for HF dataset transform\n",
+ " def transforms_im(examples):\n",
+ " examples['pixel_values'] = [transform(image) for image in examples['image']]\n",
+ " del examples['image']\n",
+ " return examples\n",
+ "\n",
+ " dataset = dataset.with_transform(transforms_im).remove_columns('label') # We don't need it \n",
+ " channels, image_size, _ = dataset['train'][0]['pixel_values'].shape\n",
+ " \n",
+ " if test:\n",
+ " dataloader = DataLoader(dataset['test'], batch_size=batch_size)\n",
+ " else:\n",
+ " dataloader = DataLoader(dataset['train'], batch_size=batch_size, shuffle=True)\n",
+ "\n",
+ " len_dataloader = len(dataloader)\n",
+ " print(f\"channels: {channels}, image dimension: {image_size}, len_dataloader: {len_dataloader}\") \n",
+ " \n",
+ " return dataloader, channels, image_size, len_dataloader"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "413a3fea",
+ "metadata": {},
+ "source": [
+ "We choose the parameters and we instantiate the dataset:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "918233da",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Dataset parameters\n",
+ "batch_size = 64\n",
+ "data_path = \"/gpfsdswork/dataset/HuggingFace/fashion_mnist/fashion_mnist/\"\n",
+ "# data_path = \"fashion_mnist\" # If you're not using Jean Zay"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "85939f9d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "train_dataloader, channels, image_size, len_dataloader = get_dataset(data_path, batch_size)\n",
+ "\n",
+ "batch_image = next(iter(train_dataloader))['pixel_values']\n",
+ "batch_image.shape"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "104db929",
+ "metadata": {},
+ "source": [
+ "We also create a function that allows us to see a batch of images:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "196370c2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def normalize_im(images):\n",
+ " shape = images.shape\n",
+ " images = images.view(shape[0], -1)\n",
+ " images -= images.min(1, keepdim=True)[0]\n",
+ " images /= images.max(1, keepdim=True)[0]\n",
+ " return images.view(shape)\n",
+ "\n",
+ "def show_images(batch):\n",
+ " plt.imshow(torch.permute(make_grid(normalize_im(batch)), (1,2,0)))\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96334e60",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "show_images(batch_image[:])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1befee67",
+ "metadata": {},
+ "source": [
+ "## Forward Diffusion\n",
+ "The aim of this part is to create a function that will add noise to any image at any step (following the DDPM diffusion process)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "231629ad",
+ "metadata": {},
+ "source": [
+ "### Beta scheduling\n",
+ "First, we create a function that will compute every betas of every steps (following a specific shedule). We will only create a function for the linear schedule (original DDPM) and the cosine schedule (improved DDPM):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0039d38d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Different type of beta schedule\n",
+ "def linear_beta_schedule(timesteps, beta_start = 0.0001, beta_end = 0.02):\n",
+ " \"\"\"\n",
+ " linar schedule from the original DDPM paper https://arxiv.org/abs/2006.11239\n",
+ " \"\"\"\n",
+ " return torch.linspace(beta_start, beta_end, timesteps)\n",
+ "\n",
+ "\n",
+ "def cosine_beta_schedule(timesteps, s=0.008):\n",
+ " \"\"\"\n",
+ " cosine schedule as proposed in https://arxiv.org/abs/2102.09672\n",
+ " \"\"\"\n",
+ " steps = timesteps + 1\n",
+ " x = torch.linspace(0, timesteps, steps)\n",
+ " alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * torch.pi * 0.5) ** 2\n",
+ " alphas_cumprod = alphas_cumprod / alphas_cumprod[0]\n",
+ " betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])\n",
+ " return torch.clip(betas, 0.0001, 0.9999)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e18d1b38",
+ "metadata": {},
+ "source": [
+ "### Constants calculation\n",
+ "We will now create a function to calculate every constants we need for our Diffusion Model. <br/>\n",
+ "Constants:\n",
+ "- $ \\beta_t $: betas\n",
+ "- $ \\sqrt{\\frac{1}{\\alpha_t}} $: sqrt_recip_alphas\n",
+ "- $ \\sqrt{\\bar{\\alpha}_t} $: sqrt_alphas_cumprod\n",
+ "- $ \\sqrt{1-\\bar{\\alpha}_t} $: sqrt_one_minus_alphas_cumprod\n",
+ "- $ \\tilde{\\beta}_t = \\beta_t\\frac{1-\\bar{\\alpha}_{t-1}}{1-\\bar{\\alpha}_t} $: posterior_variance"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "84251513",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Function to get alphas and betas\n",
+ "def get_alph_bet(timesteps, schedule=cosine_beta_schedule):\n",
+ " \n",
+ " # define beta\n",
+ " betas = schedule(timesteps)\n",
+ "\n",
+ " # define alphas \n",
+ " alphas = 1. - betas\n",
+ " alphas_cumprod = torch.cumprod(alphas, axis=0) # cumulative product of alpha\n",
+ " alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0) # corresponding to the prev const\n",
+ " sqrt_recip_alphas = torch.sqrt(1.0 / alphas)\n",
+ "\n",
+ " # calculations for diffusion q(x_t | x_{t-1}) and others\n",
+ " sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)\n",
+ " sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)\n",
+ "\n",
+ " # calculations for posterior q(x_{t-1} | x_t, x_0)\n",
+ " posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)\n",
+ " \n",
+ " const_dict = {\n",
+ " 'betas': betas,\n",
+ " 'sqrt_recip_alphas': sqrt_recip_alphas,\n",
+ " 'sqrt_alphas_cumprod': sqrt_alphas_cumprod,\n",
+ " 'sqrt_one_minus_alphas_cumprod': sqrt_one_minus_alphas_cumprod,\n",
+ " 'posterior_variance': posterior_variance\n",
+ " }\n",
+ " \n",
+ " return const_dict"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5658d8e",
+ "metadata": {},
+ "source": [
+ "### Difference between Linear and Cosine schedule\n",
+ "We can check the differences between the constants when we change the parameters:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7bfdf98c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "T = 1000\n",
+ "const_linear_dict = get_alph_bet(T, schedule=linear_beta_schedule)\n",
+ "const_cosine_dict = get_alph_bet(T, schedule=cosine_beta_schedule)\n",
+ "\n",
+ "plt.plot(np.arange(T), const_linear_dict['sqrt_alphas_cumprod'], color='r', label='linear')\n",
+ "plt.plot(np.arange(T), const_cosine_dict['sqrt_alphas_cumprod'], color='g', label='cosine')\n",
+ " \n",
+ "# Naming the x-axis, y-axis and the whole graph\n",
+ "plt.xlabel(\"Step\")\n",
+ "plt.ylabel(\"alpha_bar\")\n",
+ "plt.title(\"Linear and Cosine schedules\")\n",
+ " \n",
+ "# Adding legend, which helps us recognize the curve according to it's color\n",
+ "plt.legend()\n",
+ " \n",
+ "# To load the display window\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b1537984",
+ "metadata": {},
+ "source": [
+ "### Definition of $ q(x_t|x_0) $"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cb10e05b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# extract the values needed for time t\n",
+ "def extract(constants, batch_t, x_shape):\n",
+ " diffusion_batch_size = batch_t.shape[0]\n",
+ " \n",
+ " # get a list of the appropriate constants of each timesteps\n",
+ " out = constants.gather(-1, batch_t.cpu()) \n",
+ " \n",
+ " return out.reshape(diffusion_batch_size, *((1,) * (len(x_shape) - 1))).to(batch_t.device)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f5991bd",
+ "metadata": {},
+ "source": [
+ "Now that we have every constants that we need, we can create a function that will add noise to an image following the forward diffusion process. This function (q_sample) corresponds to $ q(x_t|x_0) $:\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28645450",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# forward diffusion (using the nice property)\n",
+ "def q_sample(constants_dict, batch_x0, batch_t, noise=None):\n",
+ " if noise is None:\n",
+ " noise = torch.randn_like(batch_x0)\n",
+ "\n",
+ " sqrt_alphas_cumprod_t = extract(constants_dict['sqrt_alphas_cumprod'], batch_t, batch_x0.shape)\n",
+ " sqrt_one_minus_alphas_cumprod_t = extract(\n",
+ " constants_dict['sqrt_one_minus_alphas_cumprod'], batch_t, batch_x0.shape\n",
+ " )\n",
+ "\n",
+ " return sqrt_alphas_cumprod_t * batch_x0 + sqrt_one_minus_alphas_cumprod_t * noise"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dcc05f40",
+ "metadata": {},
+ "source": [
+ "We can now visualize how the forward diffusion process adds noise gradually the image according to its parameters:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7ed20740",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "T = 1000\n",
+ "const_linear_dict = get_alph_bet(T, schedule=linear_beta_schedule)\n",
+ "const_cosine_dict = get_alph_bet(T, schedule=cosine_beta_schedule)\n",
+ "\n",
+ "batch_t = torch.arange(batch_size)*(T//batch_size) # get a range of timesteps from 0 to T\n",
+ "print(f\"timesteps: {batch_t}\")\n",
+ "noisy_batch_linear = q_sample(const_linear_dict, batch_image, batch_t, noise=None)\n",
+ "noisy_batch_cosine = q_sample(const_cosine_dict, batch_image, batch_t, noise=None)\n",
+ "\n",
+ "print(\"Original images:\")\n",
+ "show_images(batch_image[:])\n",
+ "\n",
+ "print(\"Noised images with linear shedule:\")\n",
+ "show_images(noisy_batch_linear[:])\n",
+ "\n",
+ "print(\"Noised images with cosine shedule:\")\n",
+ "show_images(noisy_batch_cosine[:])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "565d3c80",
+ "metadata": {},
+ "source": [
+ "## Reverse Diffusion Process"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "251808b0",
+ "metadata": {},
+ "source": [
+ "### Model definition\n",
+ "The reverse diffusion process is made by a deep learning model. We choosed a Unet model with attention. The model is optimized following some papers like [ConvNeXt](https://arxiv.org/pdf/2201.03545.pdf). You can inspect the model in the model.py file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29f00028",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from model import Unet\n",
+ "\n",
+ "model = Unet( \n",
+ " dim=28,\n",
+ " init_dim=None,\n",
+ " out_dim=None,\n",
+ " dim_mults=(1, 2, 4),\n",
+ " channels=1,\n",
+ " with_time_emb=True,\n",
+ " convnext_mult=2,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0aaf936c",
+ "metadata": {},
+ "source": [
+ "### Definition of $ p_{\\theta}(x_{t-1}|x_t) $\n",
+ "Now we need a function to retrieve $x_{t-1}$ from $x_t$ and the predicted $z_t$. It corresponds to the reverse diffusion kernel:\n",
+ "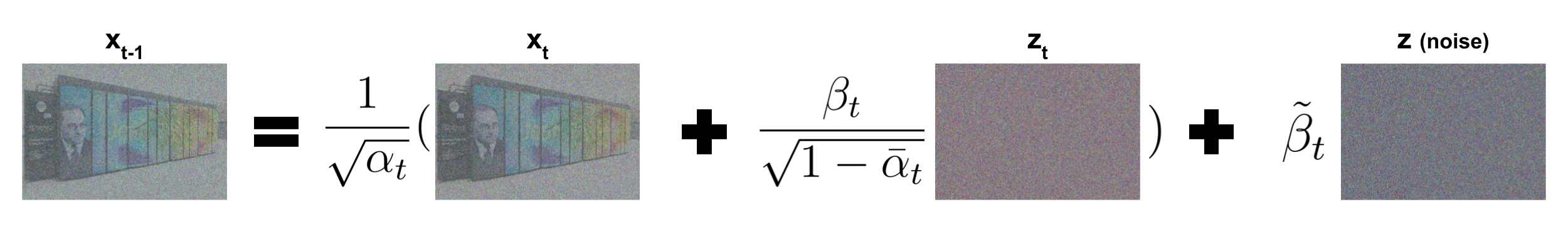"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "00443d8e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@torch.no_grad()\n",
+ "def p_sample(constants_dict, batch_xt, predicted_noise, batch_t):\n",
+ " # We first get every constants needed and send them in right device\n",
+ " betas_t = extract(constants_dict['betas'], batch_t, batch_xt.shape).to(batch_xt.device)\n",
+ " sqrt_one_minus_alphas_cumprod_t = extract(\n",
+ " constants_dict['sqrt_one_minus_alphas_cumprod'], batch_t, batch_xt.shape\n",
+ " ).to(batch_xt.device)\n",
+ " sqrt_recip_alphas_t = extract(\n",
+ " constants_dict['sqrt_recip_alphas'], batch_t, batch_xt.shape\n",
+ " ).to(batch_xt.device)\n",
+ " \n",
+ " # Equation 11 in the ddpm paper\n",
+ " # Use predicted noise to predict the mean (mu theta)\n",
+ " model_mean = sqrt_recip_alphas_t * (\n",
+ " batch_xt - betas_t * predicted_noise / sqrt_one_minus_alphas_cumprod_t\n",
+ " )\n",
+ " \n",
+ " # We have to be careful to not add noise if we want to predict the final image\n",
+ " predicted_image = torch.zeros(batch_xt.shape).to(batch_xt.device)\n",
+ " t_zero_index = (batch_t == torch.zeros(batch_t.shape).to(batch_xt.device))\n",
+ " \n",
+ " # Algorithm 2 line 4, we add noise when timestep is not 1:\n",
+ " posterior_variance_t = extract(constants_dict['posterior_variance'], batch_t, batch_xt.shape)\n",
+ " noise = torch.randn_like(batch_xt) # create noise, same shape as batch_x\n",
+ " predicted_image[~t_zero_index] = model_mean[~t_zero_index] + (\n",
+ " torch.sqrt(posterior_variance_t[~t_zero_index]) * noise[~t_zero_index]\n",
+ " ) \n",
+ " \n",
+ " # If t=1 we don't add noise to mu\n",
+ " predicted_image[t_zero_index] = model_mean[t_zero_index]\n",
+ " \n",
+ " return predicted_image"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c6e13aa1",
+ "metadata": {},
+ "source": [
+ "## Sampling "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "459df8a2",
+ "metadata": {},
+ "source": [
+ "We will now create the sampling function. Given trained model, it should generate all the images we want."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1e3cdf15",
+ "metadata": {},
+ "source": [
+ "With the reverse diffusion process and a trained model, we can now make the sampling function corresponding to this algorithm:\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "710ef636",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Algorithm 2 (including returning all images)\n",
+ "@torch.no_grad()\n",
+ "def sampling(model, shape, T, constants_dict):\n",
+ " b = shape[0]\n",
+ " # start from pure noise (for each example in the batch)\n",
+ " batch_xt = torch.randn(shape, device=DEVICE)\n",
+ " \n",
+ " batch_t = torch.ones(shape[0]) * T # create a vector with batch-size time the timestep\n",
+ " batch_t = batch_t.type(torch.int64).to(DEVICE)\n",
+ " \n",
+ " imgs = []\n",
+ "\n",
+ " for t in tqdm(reversed(range(0, T)), desc='sampling loop time step', total=T):\n",
+ " batch_t -= 1\n",
+ " predicted_noise = model(batch_xt, batch_t)\n",
+ " \n",
+ " batch_xt = p_sample(constants_dict, batch_xt, predicted_noise, batch_t)\n",
+ " \n",
+ " imgs.append(batch_xt.cpu())\n",
+ " \n",
+ " return imgs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df50675e",
+ "metadata": {},
+ "source": [
+ "## Training\n",
+ "We will instantiate every objects needed with fixed parameters here. We can try different hyperparameters by coming back here and changing the parameters."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a3884522",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Dataset parameters\n",
+ "batch_size = 64\n",
+ "data_path = \"/gpfsdswork/dataset/HuggingFace/fashion_mnist/fashion_mnist/\"\n",
+ "# data_path = \"fashion_mnist\" # If you're not using Jean Zay\n",
+ "train_dataloader, channels, image_size, len_dataloader = get_dataset(data_path, batch_size)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b6b4a2bd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "constants_dict = get_alph_bet(T, schedule=linear_beta_schedule)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ba387427",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "epochs = 3\n",
+ "T = 1000 # = T"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31933494",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model = Unet( \n",
+ " dim=image_size,\n",
+ " init_dim=None,\n",
+ " out_dim=None,\n",
+ " dim_mults=(1, 2, 4),\n",
+ " channels=channels,\n",
+ " with_time_emb=True,\n",
+ " convnext_mult=2,\n",
+ ").to(DEVICE)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "92fb2a17",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "criterion = nn.SmoothL1Loss()\n",
+ "optimizer = Adam(model.parameters(), lr=1e-4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f059d28f",
+ "metadata": {},
+ "source": [
+ "### Training loop\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4bab979d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "for epoch in range(epochs):\n",
+ " loop = tqdm(train_dataloader, desc=f\"Epoch {epoch+1}/{epochs}\")\n",
+ " for batch in loop:\n",
+ " optimizer.zero_grad()\n",
+ "\n",
+ " batch_size_iter = batch[\"pixel_values\"].shape[0]\n",
+ " batch_image = batch[\"pixel_values\"].to(DEVICE)\n",
+ "\n",
+ " # Algorithm 1 line 3: sample t uniformally for every example in the batch\n",
+ " batch_t = torch.randint(0, T, (batch_size_iter,), device=DEVICE).long()\n",
+ " \n",
+ " noise = torch.randn_like(batch_image)\n",
+ " \n",
+ " x_noisy = q_sample(constants_dict, batch_image, batch_t, noise=noise)\n",
+ " predicted_noise = model(x_noisy, batch_t)\n",
+ " \n",
+ " loss = criterion(noise, predicted_noise)\n",
+ "\n",
+ " loop.set_postfix(loss=loss.item())\n",
+ "\n",
+ " loss.backward()\n",
+ " optimizer.step()\n",
+ "\n",
+ " \n",
+ "print(\"check generation:\") \n",
+ "list_gen_imgs = sampling(model, (batch_size, channels, image_size, image_size), T, constants_dict)\n",
+ "show_images(list_gen_imgs[-1])\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2489e819",
+ "metadata": {},
+ "source": [
+ "## View of the diffusion process"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "09ce451d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def make_gif(frame_list):\n",
+ " to_pil = ToPILImage()\n",
+ " frames = [to_pil(make_grid(normalize_im(tens_im))) for tens_im in frame_list]\n",
+ " frame_one = frames[0]\n",
+ " frame_one.save(\"sampling.gif.png\", format=\"GIF\", append_images=frames[::5], save_all=True, duration=10, loop=0)\n",
+ " \n",
+ " return IPython.display.Image(filename=\"./sampling.gif.png\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4f665ac3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "make_gif(list_gen_imgs)"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "bfa40b6b",
+ "metadata": {},
+ "source": [
+ "---\n",
+ "<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "pytorch-gpu-1.13.0_py3.10.8",
+ "language": "python",
+ "name": "module-conda-env-pytorch-gpu-1.13.0_py3.10.8"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/DDPM/model.py b/DDPM/model.py
new file mode 100755
index 0000000000000000000000000000000000000000..8a2037f1dd4b8cf2f87102b969e5279f351bc359
--- /dev/null
+++ b/DDPM/model.py
@@ -0,0 +1,267 @@
+
+# <!-- TITLE --> [DDPM2] - DDPM Python classes
+# <!-- DESC --> Python classes used by DDMP Example
+# <!-- AUTHOR : Hatim Bourfoune (CNRS/IDRIS), Maxime Song (CNRS/IDRIS) -->
+
+
+import torch
+from torch import nn, einsum
+import torch.nn.functional as F
+from inspect import isfunction
+from functools import partial
+import math
+from einops import rearrange
+
+
+def exists(x):
+ return x is not None
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if isfunction(d) else d
+
+
+class Residual(nn.Module):
+ def __init__(self, fn):
+ super().__init__()
+ self.fn = fn
+
+ def forward(self, x, *args, **kwargs):
+ return self.fn(x, *args, **kwargs) + x
+
+
+def Upsample(dim):
+ return nn.ConvTranspose2d(dim, dim, 4, 2, 1)
+
+
+def Downsample(dim):
+ return nn.Conv2d(dim, dim, 4, 2, 1)
+
+
+class SinusoidalPositionEmbeddings(nn.Module):
+ def __init__(self, dim):
+ super().__init__()
+ self.dim = dim
+
+ def forward(self, time):
+ device = time.device
+ half_dim = self.dim // 2
+ embeddings = math.log(10000) / (half_dim - 1)
+ embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
+ embeddings = time[:, None] * embeddings[None, :]
+ embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
+ return embeddings
+
+
+class ConvNextBlock(nn.Module):
+ """https://arxiv.org/abs/2201.03545"""
+
+ def __init__(self, dim, dim_out, *, time_emb_dim=None, mult=2, norm=True):
+ super().__init__()
+ self.mlp = (
+ nn.Sequential(nn.GELU(), nn.Linear(time_emb_dim, dim))
+ if exists(time_emb_dim)
+ else None
+ )
+
+ self.ds_conv = nn.Conv2d(dim, dim, 7, padding=3, groups=dim)
+
+ self.net = nn.Sequential(
+ nn.GroupNorm(1, dim) if norm else nn.Identity(),
+ nn.Conv2d(dim, dim_out * mult, 3, padding=1),
+ nn.GELU(),
+ nn.GroupNorm(1, dim_out * mult),
+ nn.Conv2d(dim_out * mult, dim_out, 3, padding=1),
+ )
+
+ self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
+
+ def forward(self, x, time_emb=None):
+ h = self.ds_conv(x)
+
+ if exists(self.mlp) and exists(time_emb):
+ assert exists(time_emb), "time embedding must be passed in"
+ condition = self.mlp(time_emb)
+ h = h + rearrange(condition, "b c -> b c 1 1")
+
+ h = self.net(h)
+ return h + self.res_conv(x)
+
+
+class Attention(nn.Module):
+ def __init__(self, dim, heads=4, dim_head=32):
+ super().__init__()
+ self.scale = dim_head**-0.5
+ self.heads = heads
+ hidden_dim = dim_head * heads
+ self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
+ self.to_out = nn.Conv2d(hidden_dim, dim, 1)
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+ qkv = self.to_qkv(x).chunk(3, dim=1)
+ q, k, v = map(
+ lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
+ )
+ q = q * self.scale
+
+ sim = einsum("b h d i, b h d j -> b h i j", q, k)
+ sim = sim - sim.amax(dim=-1, keepdim=True).detach()
+ attn = sim.softmax(dim=-1)
+
+ out = einsum("b h i j, b h d j -> b h i d", attn, v)
+ out = rearrange(out, "b h (x y) d -> b (h d) x y", x=h, y=w)
+ return self.to_out(out)
+
+
+class LinearAttention(nn.Module):
+ def __init__(self, dim, heads=4, dim_head=32):
+ super().__init__()
+ self.scale = dim_head**-0.5
+ self.heads = heads
+ hidden_dim = dim_head * heads
+ self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
+
+ self.to_out = nn.Sequential(nn.Conv2d(hidden_dim, dim, 1),
+ nn.GroupNorm(1, dim))
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+ qkv = self.to_qkv(x).chunk(3, dim=1)
+ q, k, v = map(
+ lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
+ )
+
+ q = q.softmax(dim=-2)
+ k = k.softmax(dim=-1)
+
+ q = q * self.scale
+ context = torch.einsum("b h d n, b h e n -> b h d e", k, v)
+
+ out = torch.einsum("b h d e, b h d n -> b h e n", context, q)
+ out = rearrange(out, "b h c (x y) -> b (h c) x y", h=self.heads, x=h, y=w)
+ return self.to_out(out)
+
+
+class PreNorm(nn.Module):
+ def __init__(self, dim, fn):
+ super().__init__()
+ self.fn = fn
+ self.norm = nn.GroupNorm(1, dim)
+
+ def forward(self, x):
+ x = self.norm(x)
+ return self.fn(x)
+
+
+class Unet(nn.Module):
+ def __init__(
+ self,
+ dim,
+ init_dim=None,
+ out_dim=None,
+ dim_mults=(1, 2, 4, 8),
+ channels=3,
+ with_time_emb=True,
+ convnext_mult=2,
+ ):
+ super().__init__()
+
+ # determine dimensions
+ self.channels = channels
+
+ init_dim = default(init_dim, dim // 3 * 2)
+ self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3)
+
+ dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
+ in_out = list(zip(dims[:-1], dims[1:]))
+
+ block_klass = partial(ConvNextBlock, mult=convnext_mult)
+
+ # time embeddings
+ if with_time_emb:
+ time_dim = dim * 4
+ self.time_mlp = nn.Sequential(
+ SinusoidalPositionEmbeddings(dim),
+ nn.Linear(dim, time_dim),
+ nn.GELU(),
+ nn.Linear(time_dim, time_dim),
+ )
+ else:
+ time_dim = None
+ self.time_mlp = None
+
+ # layers
+ self.downs = nn.ModuleList([])
+ self.ups = nn.ModuleList([])
+ num_resolutions = len(in_out)
+
+ for ind, (dim_in, dim_out) in enumerate(in_out):
+ is_last = ind >= (num_resolutions - 1)
+
+ self.downs.append(
+ nn.ModuleList(
+ [
+ block_klass(dim_in, dim_out, time_emb_dim=time_dim),
+ block_klass(dim_out, dim_out, time_emb_dim=time_dim),
+ Residual(PreNorm(dim_out, LinearAttention(dim_out))),
+ Downsample(dim_out) if not is_last else nn.Identity(),
+ ]
+ )
+ )
+
+ mid_dim = dims[-1]
+ self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
+ self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
+ self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
+
+ for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):
+ is_last = ind >= (num_resolutions - 1)
+
+ self.ups.append(
+ nn.ModuleList(
+ [
+ block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),
+ block_klass(dim_in, dim_in, time_emb_dim=time_dim),
+ Residual(PreNorm(dim_in, LinearAttention(dim_in))),
+ Upsample(dim_in) if not is_last else nn.Identity(),
+ ]
+ )
+ )
+
+ out_dim = default(out_dim, channels)
+ self.final_conv = nn.Sequential(
+ block_klass(dim, dim), nn.Conv2d(dim, out_dim, 1)
+ )
+
+ def forward(self, x, time):
+ x = self.init_conv(x)
+
+ t = self.time_mlp(time) if exists(self.time_mlp) else None
+
+ h = []
+
+ # downsample
+ for block1, block2, attn, downsample in self.downs:
+ x = block1(x, t)
+ x = block2(x, t)
+ x = attn(x)
+ h.append(x)
+ x = downsample(x)
+
+ # bottleneck
+ x = self.mid_block1(x, t)
+ x = self.mid_attn(x)
+ x = self.mid_block2(x, t)
+
+ # upsample
+ for block1, block2, attn, upsample in self.ups:
+ x = torch.cat((x, h.pop()), dim=1)
+ x = block1(x, t)
+ x = block2(x, t)
+ x = attn(x)
+ x = upsample(x)
+
+ return self.final_conv(x)
diff --git a/DDPM/requirements.txt b/DDPM/requirements.txt
new file mode 100755
index 0000000000000000000000000000000000000000..41efc0a310e206df42160a52a87c10feb76391f1
--- /dev/null
+++ b/DDPM/requirements.txt
@@ -0,0 +1,8 @@
+python==3.10
+jupyterlab
+pytorch
+torchvision
+tqdm
+matplotlib
+einops
+datasets
\ No newline at end of file
diff --git a/DDPM/sampling.gif.png b/DDPM/sampling.gif.png
new file mode 100755
index 0000000000000000000000000000000000000000..483735ef43873375f18b9f713bb94bd1c19284a5
Binary files /dev/null and b/DDPM/sampling.gif.png differ
diff --git a/Optimization/01-Apprentissages-rapides-et-Optimisations.ipynb b/Optimization/01-Apprentissages-rapides-et-Optimisations.ipynb
new file mode 100755
index 0000000000000000000000000000000000000000..5fdd218420582175393528d10236417152658044
--- /dev/null
+++ b/Optimization/01-Apprentissages-rapides-et-Optimisations.ipynb
@@ -0,0 +1,1238 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EBL97zOSNOUb"
+ },
+ "source": [
+ "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
+ "\n",
+ "# <!-- TITLE --> [OPT1] - Training setup optimization\n",
+ "<!-- DESC --> The goal of this notebook is to go through a typical deep learning model training\n",
+ "\n",
+ "<!-- AUTHOR : Kamel Guerda (CNRS/IDRIS), Léo Hunout (CNRS/IDRIS) -->\n",
+ "\n",
+ "## Objectives :\n",
+ "\n",
+ "\n",
+ "**Practice lab : Optimize your training process**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wmsmK2lGelCE"
+ },
+ "source": [
+ "## Introduction\n",
+ "\n",
+ "This Lab takes place as a pratical exercice of the [fidle](https://fidle.cnrs.fr/) online course N°16.\n",
+ "\n",
+ "\n",
+ "The goal of this notebook is to go through a typical deep learning model training. We will see what can be changed to optimize this training setup but also good practices to make more efficient experiments.\n",
+ "\n",
+ "\n",
+ "This notebook makes use of:\n",
+ "- The CIFAR10 dataset\n",
+ "- A Resnet model\n",
+ "- Pytorch\n",
+ "- A GPU (the notebook can be ran on Jean-Zay if you have an account, on Google collab with a 16go gpu or at home with a dedicated gpu by scaling down the batch_size)\n",
+ "\n",
+ "In particular we will work on:\n",
+ "- the dataloader strategy used to load data\n",
+ "- the model initial weights, in particular using a pretrained model\n",
+ "- the learning rate and learning rate scheduler\n",
+ "- the optimizer\n",
+ "- visualizing and comparing results using python, tensorboard\n",
+ "- various good practices/reminders\n",
+ "\n",
+ "> First, you can do a complete execution of the notebook.\n",
+ "\n",
+ "> **Then comeback from the start and follow the instructions to edit various components for better performance. You can also change them during the first execution if you have some intuitions about what should be changed and how.**\n",
+ "\n",
+ "> **In order to compare performance, only change the xxx_optim variables which are the one you will use in your optimized training**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "UrJW8d_lqZ-l"
+ },
+ "outputs": [],
+ "source": [
+ "!nvidia-smi"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "527LDYwLf9gB"
+ },
+ "source": [
+ "## Few imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "mPEZLMywejMG"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import time\n",
+ "import random\n",
+ "import numpy as np\n",
+ "\n",
+ "import torch\n",
+ "from torch.cuda.amp import autocast, GradScaler\n",
+ "from torch.optim.lr_scheduler import _LRScheduler\n",
+ "\n",
+ "import torchvision\n",
+ "import torchvision.transforms as transforms\n",
+ "import torchvision.models as models\n",
+ "from torchvision.models.resnet import ResNet18_Weights\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "from datetime import datetime\n",
+ "from torch.utils.tensorboard import SummaryWriter"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "G_DozO12fv8o"
+ },
+ "source": [
+ "## Fix random seeds\n",
+ "In order to have experiment reproductibility, it is a good practice to fix the random number generators seeds.\n",
+ "\n",
+ "Warning : there might be more seeds to set than you expect! Maths,visualization,transformations libraries, ..."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Y9jOl-D8ejWw"
+ },
+ "outputs": [],
+ "source": [
+ "random.seed(123)\n",
+ "np.random.seed(123)\n",
+ "torch.manual_seed(123)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9nZlyar5NOUr"
+ },
+ "source": [
+ "## Some functions\n",
+ "\n",
+ "Below we define a few functions that will be used further in the notebook. \n",
+ "\n",
+ "**Do not change them unless you know what and why you are doing it.**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "JFQtFuDWNOUt"
+ },
+ "outputs": [],
+ "source": [
+ "def iter_dataloader(dataloader, epochs, args):\n",
+ " for epoch in range(epochs):\n",
+ " for i, (images, labels) in enumerate(dataloader):\n",
+ " # distribution of images and labels to all GPUs\n",
+ " images = images.to(args['device'], non_blocking=True)\n",
+ " labels = labels.to(args['device'], non_blocking=True)\n",
+ " \n",
+ "def evaluate(dataloader, model, criterion, args):\n",
+ " '''\n",
+ " A simple loop for evaluation\n",
+ " '''\n",
+ " loss = 0\n",
+ " correct = 0\n",
+ " total = 0\n",
+ " with torch.no_grad():\n",
+ " for i, (images, labels) in enumerate(dataloader):\n",
+ " # distribution of images and labels to all GPUs\n",
+ " images = images.to(args['device'], non_blocking=True)\n",
+ " labels = labels.to(args['device'], non_blocking=True)\n",
+ " outputs = model(images)\n",
+ " loss = criterion(outputs,labels)\n",
+ " _, predicted = torch.max(outputs.data, 1)\n",
+ "\n",
+ " loss += loss\n",
+ " total += labels.size(0)\n",
+ " correct += (predicted == labels).sum().item()\n",
+ " loss = (loss/total).item()\n",
+ " accuracy = (correct/total)*100\n",
+ " return loss, accuracy\n",
+ "\n",
+ "def train_default(train_loader, val_loader, model, optimizer, criterion, args):\n",
+ " '''\n",
+ " The default simple training loop\n",
+ " '''\n",
+ " train_losses = []\n",
+ " train_accuracies = []\n",
+ " val_losses = []\n",
+ " val_accuracies = []\n",
+ " time_start = time.time()\n",
+ " for epoch in range(args['epochs']):\n",
+ " print(\"Epoch \", epoch)\n",
+ " for i, (images, labels) in enumerate(train_loader):\n",
+ " # distribution of images and labels to all GPUs\n",
+ " images = images.to(args['device'], non_blocking=True)\n",
+ " labels = labels.to(args['device'], non_blocking=True)\n",
+ " \n",
+ " # Zero the parameter gradients\n",
+ " optimizer.zero_grad()\n",
+ "\n",
+ " # Forward pass\n",
+ " outputs = model(images)\n",
+ " loss = criterion(outputs, labels)\n",
+ "\n",
+ " # Backward pass\n",
+ " loss.backward()\n",
+ "\n",
+ " # Optimize\n",
+ " optimizer.step()\n",
+ "\n",
+ " # Evaluate at the end of the epoch on the train set\n",
+ " train_loss, train_accuracy = evaluate(train_loader, model, criterion, args)\n",
+ " print(\"\\t Train loss : \", train_loss, \"& Train accuracy : \", train_accuracy)\n",
+ " train_losses.append(train_loss)\n",
+ " train_accuracies.append(train_accuracy) \n",
+ " \n",
+ " # Evaluate at the end of the epoch on the val set\n",
+ " val_loss, val_accuracy = evaluate(val_loader, model, criterion, args)\n",
+ " print(\"\\t Validation loss : \", val_loss, \"& Validation accuracy : \", val_accuracy)\n",
+ " val_losses.append(val_loss)\n",
+ " val_accuracies.append(val_accuracy)\n",
+ " \n",
+ " duration = time.time() - time_start\n",
+ " print('Finished Training in:', duration, 'seconds with mean epoch duration:', duration/args['epochs'], ' seconds')\n",
+ " results = {'model':model,\n",
+ " 'train_losses': train_losses,\n",
+ " 'train_accuracies': train_accuracies,\n",
+ " 'val_losses': val_losses,\n",
+ " 'val_accuracies': val_accuracies,\n",
+ " 'duration':duration}\n",
+ " return results\n",
+ "\n",
+ "def explore_lrs(dataloader, \n",
+ " model, \n",
+ " optimizer,\n",
+ " args,\n",
+ " min_learning_rate_power=-8, \n",
+ " max_learning_rate_power = 1,\n",
+ " num_lrs=10,\n",
+ " steps_per_lr=50):\n",
+ " \n",
+ " lrs = np.logspace(min_learning_rate_power, max_learning_rate_power, num=num_lrs)\n",
+ " print(\"Learning rate space : \", lrs)\n",
+ " model_init_state = model.state_dict()\n",
+ "\n",
+ " lrs_losses, lrs_metric_avg, lrs_metric_var =[], [],[]\n",
+ " \n",
+ " # Iterate through learning rates to test\n",
+ " for lr in lrs:\n",
+ " print(\"Testing lr:\", '{:.2e}'.format(lr))\n",
+ " # Reset model\n",
+ " model.load_state_dict(model_init_state)\n",
+ "\n",
+ " # Change learning rate in optimizer\n",
+ " for group in optimizer.param_groups:\n",
+ " group['lr'] = lr\n",
+ "\n",
+ " # Reset metric tracking\n",
+ " lr_losses =[]\n",
+ "\n",
+ " # Training steps\n",
+ " for step in range(steps_per_lr):\n",
+ " images, labels = next(iter(dataloader))\n",
+ " # distribution of images and labels to all GPUs\n",
+ " images = images.to(args['device'], non_blocking=True)\n",
+ " labels = labels.to(args['device'], non_blocking=True)\n",
+ " optimizer.zero_grad()\n",
+ " outputs = model(images)\n",
+ " loss = criterion(outputs, labels)\n",
+ " loss.backward()\n",
+ " optimizer.step()\n",
+ " lr_losses.append(loss.item())\n",
+ " print(lr_losses)\n",
+ "\n",
+ " # Compute loss average for lr\n",
+ " lr_loss_avg = np.mean(lr_losses) \n",
+ " lr_loss_avg = lr_losses[-1]\n",
+ "\n",
+ " lrs_losses.append(lr_loss_avg)\n",
+ "\n",
+ " # Compute metric (discounted average gradient of the loss)\n",
+ " lr_gradients = np.gradient(lr_losses)\n",
+ " lr_metric_avg = np.mean(lr_gradients)\n",
+ " lr_metric_var = np.var(lr_gradients)\n",
+ " lrs_metric_avg.append(lr_metric_avg) \n",
+ " lrs_metric_var.append(lr_metric_var)\n",
+ " model.load_state_dict(model_init_state)\n",
+ "\n",
+ " return lrs, lrs_losses, lrs_metric_avg, lrs_metric_var\n",
+ "\n",
+ "def plot_eval(lrs, lrs_losses, lrs_metric_avg, lrs_metric_var):\n",
+ " print(\"lrs: \", lrs)\n",
+ " print(\"lrs_losses: \", lrs_losses)\n",
+ " print(\"lrs_metric_avg: \", lrs_metric_avg)\n",
+ " print(\"lrs_metric_var: \", lrs_metric_var)\n",
+ " fig, axs = plt.subplots(3, figsize=(10,15))\n",
+ "\n",
+ " axs[0].plot(lrs, lrs_losses, color='blue', label=\"losses_avg\")\n",
+ " axs[0].set_xlabel('learning rate', fontsize=15)\n",
+ " axs[0].set_ylabel('Loss', fontsize=15)\n",
+ " axs[0].set_xscale('log')\n",
+ " axs[0].set_yscale('symlog')\n",
+ " axs[0].set_ylim([0, min(lrs_losses)*100])\n",
+ "\n",
+ " axs[1].plot(lrs, lrs_metric_avg, color='red', label=\"discounted_metric_avg\")\n",
+ " axs[1].hlines(y=0, xmin=lrs[0], xmax=lrs[-1], linewidth=2, color='black')\n",
+ " axs[1].set_xlabel('learning rate', fontsize=15)\n",
+ " axs[1].set_ylabel('Metric average', fontsize=15)\n",
+ " axs[1].set_xscale('log')\n",
+ " axs[1].set_yscale('symlog')\n",
+ " axs[1].set_ylim([-abs(lrs_metric_avg[0])*100, abs(lrs_metric_avg[0])*100])\n",
+ "\n",
+ " axs[2].plot(lrs, lrs_metric_var, color='green', label=\"discounted_metric_var\")\n",
+ " axs[2].set_xlabel('learning rate', fontsize=15)\n",
+ " axs[2].set_ylabel('Metric variance', fontsize=15)\n",
+ " axs[2].set_xscale('log')\n",
+ " axs[2].set_yscale('symlog')\n",
+ " axs[2].set_ylim([0, min(lrs_metric_var)*1000])\n",
+ "\n",
+ " plt.show()\n",
+ " \n",
+ "def compare_trainings(results_default, results_optim):\n",
+ " fig, axs = plt.subplots(2, figsize=(10,10))\n",
+ " fig.suptitle('Performance comparison', fontsize=18) \n",
+ " \n",
+ " train_alpha = 0.5\n",
+ " \n",
+ " # Validation losses \n",
+ " axs[0].plot(range(len(results_default['val_losses'])), results_default['val_losses'], color='blue', label=\"default val\")\n",
+ " axs[0].plot(range(len(results_optim['val_losses'])), results_optim['val_losses'], color='red', label=\"optim val\")\n",
+ "\n",
+ " # Training losses \n",
+ " axs[0].plot(range(len(results_default['train_losses'])), results_default['train_losses'], color='blue', label=\"default train\", linestyle='--', alpha = train_alpha)\n",
+ " axs[0].plot(range(len(results_optim['train_losses'])), results_optim['train_losses'], color='red', label=\"optim train\", linestyle='--', alpha = train_alpha)\n",
+ " \n",
+ " axs[0].set_xlabel('Epochs', fontsize=14)\n",
+ " axs[0].set_ylabel('Loss', fontsize=14)\n",
+ " axs[0].set_xscale('linear')\n",
+ " axs[0].set_yscale('linear')\n",
+ " max_loss = max(results_default['train_losses']+results_default['val_losses']+results_optim['train_losses']+results_optim['val_losses'])\n",
+ " axs[0].set_ylim([0, max_loss])\n",
+ " axs[0].legend(loc=\"upper right\")\n",
+ " \n",
+ " # Validation accuracies\n",
+ " axs[1].plot(range(len(results_default['val_accuracies'])), results_default['val_accuracies'], color='blue', label=\"default val\")\n",
+ " axs[1].plot(range(len(results_optim['val_accuracies'])), results_optim['val_accuracies'], color='red', label=\"optim val\")\n",
+ "\n",
+ " # Training default accuracies\n",
+ " axs[1].plot(range(len(results_default['train_accuracies'])), results_default['train_accuracies'], color='blue', label=\"default train\", linestyle='--', alpha=train_alpha)\n",
+ " axs[1].plot(range(len(results_optim['train_accuracies'])), results_optim['train_accuracies'], color='red', label=\"optim train\", linestyle='--', alpha=train_alpha)\n",
+ " \n",
+ " axs[1].set_xlabel('Epochs', fontsize=15)\n",
+ " axs[1].set_ylabel('Accuracy', fontsize=15)\n",
+ " axs[1].set_xscale('linear')\n",
+ " axs[1].set_yscale('linear')\n",
+ " axs[1].set_ylim([0, 100])\n",
+ " axs[1].legend(loc=\"lower right\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "USjwbaqvfvT9"
+ },
+ "source": [
+ "## Training configuration variables\n",
+ "For the first run, you can let all the values given by default.\n",
+ "For the optimized run, you could changing some parameters. \n",
+ ">In particular, you will have to change :\n",
+ ">- the batch_size\n",
+ ">- the learning rate"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "vJRP94hFejjg"
+ },
+ "outputs": [],
+ "source": [
+ "args = {\n",
+ " 'batch_size':64,\n",
+ " 'epochs': 10,\n",
+ " 'image_size': 224,\n",
+ " 'learning_rate': 0.001,\n",
+ " 'momentum': 0.9,\n",
+ " 'weight_decay': 0.0001,\n",
+ " 'download': True,\n",
+ " 'device': torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\"),\n",
+ " 'dataset_root_dir': os.getcwd(),\n",
+ "}\n",
+ "\n",
+ "#################################################\n",
+ "############# Modify the code below #############\n",
+ "#################################################\n",
+ "args_optim = {\n",
+ " 'batch_size':64,\n",
+ " 'epochs': 10,\n",
+ " 'image_size': 224,\n",
+ " 'learning_rate': 0.001,\n",
+ " 'momentum': 0.9,\n",
+ " 'weight_decay': 0.0001,\n",
+ " 'download': True,\n",
+ " 'device': torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\"),\n",
+ " 'dataset_root_dir': os.getcwd(), \n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pfQP_RbKAU6N"
+ },
+ "source": [
+ "<details>\n",
+ "<summary>Spoiler (click to reveal)</summary>\n",
+ "\n",
+ "```python\n",
+ "args_optim = {\n",
+ " 'batch_size':512,\n",
+ " 'epochs': 10,\n",
+ " 'image_size': 224,\n",
+ " 'learning_rate': 0.001,\n",
+ " 'momentum': 0.9,\n",
+ " 'weight_decay': 0.01,\n",
+ " 'download': True,\n",
+ " 'device': torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\"),\n",
+ " 'dataset_root_dir': os.getcwd(), \n",
+ "}\n",
+ "``` \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "b5CbvfOAfnQ9"
+ },
+ "source": [
+ "## Data transformation and augmentation\n",
+ "Below, we define the transformations to apply to each image when loaded.\n",
+ "It can serve three main purposes:\n",
+ "- having the data in the desired format for the model (systematic transformation)\n",
+ "- correcting/normalizing the data (systematic transformation)\n",
+ "- artificially increasing the amount of data by transforming the data (random transformation)\n",
+ "\n",
+ "Warning : the evaluation dataset should always be the same so you should not apply random transformations to it.\n",
+ "\n",
+ "> Enrich the transformations by using the provided by torchvision : https://pytorch.org/vision/0.12/transforms.html\n",
+ "\n",
+ "> **Change transform_optim and val_transform_optim only**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "I8d51hBifiDH"
+ },
+ "outputs": [],
+ "source": [
+ "transform = transforms.Compose([transforms.ToTensor()]) # convert the PIL Image to a tensor\n",
+ "val_transform = transforms.Compose([transforms.ToTensor()]) # convert the PIL Image to a tensor\n",
+ " \n",
+ "#################################################\n",
+ "############# Modify the code below #############\n",
+ "#################################################\n",
+ "transform_optim = transforms.Compose([transforms.ToTensor()]) # convert the PIL Image to a tensor\n",
+ "val_transform_optim = transforms.Compose([transforms.ToTensor()]) # convert the PIL Image to a tensor"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VZp4xMdxrJs9"
+ },
+ "source": [
+ "<details>\n",
+ "<summary>Spoiler</summary>\n",
+ "\n",
+ " \n",
+ "```python\n",
+ "transform_optim = transforms.Compose([ \n",
+ " transforms.RandomHorizontalFlip(), # Horizontal Flip - Data Augmentation\n",
+ " transforms.ToTensor() # convert the PIL Image to a tensor\n",
+ " ])\n",
+ "\n",
+ "val_transform_optim = transforms.Compose([\n",
+ " transforms.ToTensor() # convert the PIL Image to a tensor\n",
+ " ])\n",
+ "``` \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rYIkzw02fqnd"
+ },
+ "source": [
+ "## Dataset\n",
+ "In the cell below, we define the dataset.\n",
+ "Here we have two subset:\n",
+ "- a training subset for model optimization\n",
+ "- a test subset for model evaluation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "RImKrDEwe-Y7"
+ },
+ "outputs": [],
+ "source": [
+ "train_dataset = torchvision.datasets.CIFAR10(root=args['dataset_root_dir']+'/CIFAR_10', train=True, download=args['download'], transform=transform)\n",
+ "\n",
+ "val_dataset = torchvision.datasets.CIFAR10(root=args['dataset_root_dir']+'/CIFAR_10', train=False, download=args['download'], transform=val_transform)\n",
+ "\n",
+ "train_dataset_optim = torchvision.datasets.CIFAR10(root=args_optim['dataset_root_dir']+'/CIFAR_10', train=True, download=args_optim['download'], transform=transform_optim)\n",
+ "\n",
+ "val_dataset_optim = torchvision.datasets.CIFAR10(root=args_optim['dataset_root_dir']+'/CIFAR_10', train=False, download=args_optim['download'], transform=val_transform_optim)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tFMn2WRHgDko"
+ },
+ "source": [
+ "## Dataloader\n",
+ "The DataLoader class in PyTorch is responsible for loading and batching data from a dataset object, such as a PyTorch tensor or a NumPy array.\n",
+ "It works by creating a Python iterable over the dataset and yielding a batch of data at each iteration.\n",
+ "\n",
+ "Those batches will be fed to the model for training or inference.\n",
+ "\n",
+ "The DataLoader class also provides various options for shuffling, batching, and parallelizing the data loading process, making it a useful tool for efficient and flexible data handling in PyTorch.\n",
+ "> Take a look at the DataLoader documentation : https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader\n",
+ "\n",
+ "> Optimize the dataloader by taking advantage of parallelism and smart use of computational ressources :\n",
+ ">- batch_size\n",
+ ">- pin_memory\n",
+ ">- prefetch_factor \n",
+ ">- persistent_workers \n",
+ ">- num_workers"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "r9Mp67_fgIGN"
+ },
+ "outputs": [],
+ "source": [
+ "train_loader = torch.utils.data.DataLoader(dataset=train_dataset,\n",
+ " batch_size=args['batch_size'],\n",
+ " shuffle=True,\n",
+ " drop_last=True)\n",
+ "\n",
+ "val_loader = torch.utils.data.DataLoader(dataset=val_dataset, \n",
+ " batch_size=args['batch_size'],\n",
+ " shuffle=False,\n",
+ " drop_last=True)\n",
+ "\n",
+ "#################################################\n",
+ "############# Modify the code below #############\n",
+ "#################################################\n",
+ "train_loader_optim = torch.utils.data.DataLoader(dataset=train_dataset,\n",
+ " batch_size=args_optim['batch_size'],\n",
+ " shuffle=True,\n",
+ " drop_last=True)\n",
+ "\n",
+ "val_loader_optim = torch.utils.data.DataLoader(dataset=val_dataset, \n",
+ " batch_size=args_optim['batch_size'],\n",
+ " shuffle=False,\n",
+ " drop_last=True)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "mvMxD20VNOU8"
+ },
+ "outputs": [],
+ "source": [
+ "%timeit -r 1 -n 1 iter_dataloader(train_loader, 1, args)\n",
+ "%timeit -r 1 -n 1 iter_dataloader(train_loader_optim, 1, args_optim)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Vegex5s0gIVF"
+ },
+ "source": [
+ "<details>\n",
+ "<summary>Spoiler</summary>\n",
+ "WIP : Quelques explications\n",
+ "\n",
+ "```python\n",
+ "train_loader_optim = torch.utils.data.DataLoader(dataset=train_dataset_optim,\n",
+ " batch_size=args_optim['batch_size'],\n",
+ " shuffle=True,\n",
+ " drop_last=True,\n",
+ " num_workers=10,\n",
+ " persistent_workers=True,\n",
+ " pin_memory=True,\n",
+ " prefetch_factor=10)\n",
+ "\n",
+ "val_loader_optim = torch.utils.data.DataLoader(dataset=val_dataset_optim, \n",
+ " batch_size=args_optim['batch_size'],\n",
+ " shuffle=False,\n",
+ " drop_last=True,\n",
+ " num_workers=10,\n",
+ " persistent_workers=True,\n",
+ " pin_memory=True,\n",
+ " prefetch_factor=10)\n",
+ "``` \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2_yVrvKvgIt0"
+ },
+ "source": [
+ "## Model\n",
+ "\n",
+ "> Do not forget to verify that you use the right compute ressources for your model\n",
+ "\n",
+ "> By default, the model resnet18 is initialized with random weights but you could try using a pretrained model : https://pytorch.org/vision/main/models/generated/torchvision.models.resnet18.html#torchvision.models.ResNet18_Weights"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "NCQgZOx6gI6Q"
+ },
+ "outputs": [],
+ "source": [
+ "model = models.resnet18()\n",
+ "model = model.to(args['device'])\n",
+ "model.name = 'Resnet-18'\n",
+ "print(\"Stock model on device:\", next(model.parameters()).device)\n",
+ "#################################################\n",
+ "############# Modify the code below #############\n",
+ "#################################################\n",
+ "model_optim = models.resnet18()\n",
+ "model_optim = model_optim.to(args_optim['device'])\n",
+ "model_optim.name = 'Resnet-18'\n",
+ "print(\"Optimized model on device:\", next(model_optim.parameters()).device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "p4umlBOmghZX"
+ },
+ "source": [
+ "<details>\n",
+ "<summary>Spoiler</summary>\n",
+ " \n",
+ "```python\n",
+ "model_optim = models.resnet18(ResNet18_Weights)\n",
+ "model_optim = model_optim.to(args_optim['device'])\n",
+ "model_optim.name = 'Resnet-18'\n",
+ "print(\"Optimized model on device:\", next(model_optim.parameters()).device)\n",
+ "``` \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ur1uA38ugiBl"
+ },
+ "source": [
+ "## Loss\n",
+ "We use a standart loss for classification.\n",
+ "\n",
+ "For the comparison, if you change the loss, change it for both.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "sxSZEKKogiJe"
+ },
+ "outputs": [],
+ "source": [
+ "criterion = torch.nn.CrossEntropyLoss()\n",
+ "criterion_optim = torch.nn.CrossEntropyLoss()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qJadxpf_giT4"
+ },
+ "source": [
+ "## Optimizer\n",
+ "\n",
+ "> In order to speed up the training, you can try to use a different optimizer: https://pytorch.org/docs/stable/optim.html#base-class"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "3fsqrktLgiaJ"
+ },
+ "outputs": [],
+ "source": [
+ "optimizer = torch.optim.SGD(model.parameters(), args['learning_rate'], args['momentum'], args['weight_decay'])\n",
+ "#################################################\n",
+ "############# Modify the code below #############\n",
+ "#################################################\n",
+ "optimizer_optim = torch.optim.SGD(model.parameters(), args_optim['learning_rate'], args_optim['momentum'], args_optim['weight_decay'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZEcyEt1Ig21T"
+ },
+ "source": [
+ "<details>\n",
+ "<summary>Spoiler</summary>\n",
+ "\n",
+ "```python\n",
+ "optimizer_optim = torch.optim.AdamW(model_optim.parameters(), lr = args_optim['learning_rate'], weight_decay=args_optim['weight_decay'])\n",
+ "```\n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3wcKevBct--P"
+ },
+ "source": [
+ "## Learning rate scheduler\n",
+ "In order to adjust the learning rate over iterations/epochs, we can make use of a learning rate scheduler.\n",
+ "\n",
+ "To use a LR scheduler, you will need to :\n",
+ "- instantiate the scheduler (in the coding cell below)\n",
+ "- adapt the training loop (in the \"Training\" section)\n",
+ "\n",
+ "Take a look at this page : https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate which: \n",
+ "- describes how to use a scheduler (warning : some scheduler are updated at a step level and others at an epoch level)\n",
+ "- lists the available schedulers (you could also create your own starting from the _LRScheduler class)\n",
+ "\n",
+ "> **You can define your scheduler here.**\n",
+ "\n",
+ "> **You will have to modify the training loop later on.**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "ISanTSFWuBps"
+ },
+ "outputs": [],
+ "source": [
+ "scheduler = None\n",
+ "#################################################\n",
+ "############# Modify the code below #############\n",
+ "#################################################\n",
+ "scheduler_optim = None"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KvnPRnuJvjVx"
+ },
+ "source": [
+ "<details>\n",
+ "<summary>Spoiler</summary>\n",
+ " \n",
+ "```python\n",
+ "scheduler_optim = torch.optim.lr_scheduler.OneCycleLR(optimizer_optim, \n",
+ " max_lr=args_optim['learning_rate'], \n",
+ " steps_per_epoch = len(train_loader_optim), \n",
+ " epochs=args_optim['epochs'])\n",
+ "``` \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YxPlz4U3g9Yv"
+ },
+ "source": [
+ "## Model training (reference performances)\n",
+ "Once we have all our main actors, we can setup the stage that is our training loop.\n",
+ "\n",
+ "Below is used a typical loop as you can find in https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html\n",
+ "> **Run it a first time to have a performance baseline with all the default values.**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "cy1QzZxwNOVH"
+ },
+ "outputs": [],
+ "source": [
+ "results_default = train_default(train_loader, val_loader, model, optimizer, criterion, args)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7vU3uot9v3hc"
+ },
+ "source": [
+ "## Speeding up the hyperparameter search : Learning Rate Finder\n",
+ "Wether we are using a scheduler or not, we need to determine either : \n",
+ "- the constant learning rate you want to use, \n",
+ "- or the maximum learning rate used by the scheduler.\n",
+ "\n",
+ "If you are in the first situation, you just want a good all-rounder learning rate to have a relatively fast conversion and minimize the oscillations at the end of the convergence.\n",
+ "\n",
+ "In the second situation, you can focus more on having the fastest inital convergence as the oscillations will be generally taken care by a decreasing learning rate strategy. Thus, we want the highest maximum learning rate possible.\n",
+ "\n",
+ "It would be ideal to find the best learning rate quickly in order to speedup our hyperparameter search.\n",
+ "Various strategy more or less complex exists to find an estimate of this value.\n",
+ "Below, we try to find the learning rate by doing a few steps on a range of learning rates. We evaluate each learning rate to determine the best one to choose for our full training.\n",
+ "\n",
+ "> **As this step can take quite some time, we provided you with some values for the default config which you are not supposed to change anyway. You can find them in the next spoiler**\n",
+ "\n",
+ "> **Uncomment explore_lrs to rerun the exploration, otherwise you can reuse the given values.**\n",
+ "\n",
+ "> **Be careful to re-run this cell to reset the model and optimizer,... to have a \"fresh\" exploration each time**\n",
+ "\n",
+ "> **Also if you change the optimizer for the optimized run, change it also here to find the best learning rate for that optimizer.** Or rerun the cell where you defined it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "kG45YwwY5Hut"
+ },
+ "outputs": [],
+ "source": [
+ "lrs, lrs_losses, lrs_metric_avg, lrs_metric_var = explore_lrs(train_loader_optim,\n",
+ " model_optim, \n",
+ " optimizer_optim,\n",
+ " args_optim,\n",
+ " min_learning_rate_power=-6, \n",
+ " max_learning_rate_power = 1,\n",
+ " num_lrs=8,\n",
+ " steps_per_lr=100) "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pDmkRbleNOVL"
+ },
+ "source": [
+ "<details>\n",
+ "<summary>Spoiler</summary>\n",
+ " \n",
+ "```python\n",
+ "lrs=[1.e-06, 1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01]\n",
+ "lrs_losses= [7.502097129821777, 7.22658634185791, 5.24326229095459, 1.7600191831588745, 1.4037541151046753, 2.136382579803467, 2.1029751300811768, 446.49951171875]\n",
+ "lrs_metric_avg=[0.0017601490020751954, -0.005245075225830078, -0.041641921997070314, -0.07478624820709229, -0.007052739858627319, 0.04763659238815308, 0.03924872875213623, 9.939403522014619]\n",
+ "lrs_metric_var=[0.0006510000222988311, 0.0004144988674492198, 0.000668689274974986, 0.013876865854565344, 0.001481160611942387, 0.3384368026131311, 0.8817071610439394, 2157852536609.2454]\n",
+ "``` \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "gpFPWNZXv670"
+ },
+ "outputs": [],
+ "source": [
+ "plot_eval(lrs, lrs_losses, lrs_metric_avg, lrs_metric_var)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pVw14RZ9NOVO"
+ },
+ "source": [
+ "## Optimize the training loop\n",
+ "\n",
+ "> Adapt the dataset transformations, batch_size & dataloader, lr & lr_scheduler, and optimizer in order to achieve better classification results in less time. \n",
+ "\n",
+ "> Change this training loop to include:\n",
+ "> - a learning rate scheduler : https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate\n",
+ "> - a strategy such as early stopping or patience : https://www.kaggle.com/code/akhileshrai/tutorial-early-stopping-vanilla-rnn-pytorch?scriptVersionId=26440051&cellId=10#4.-Early-Stopping\n",
+ "\n",
+ "> **Also think about changing the call to the function if you added arguments.**\n",
+ "\n",
+ "> For you, we added automatic mixed precision which will be seen in the next course\n",
+ "\n",
+ "> **BEFORE RUNNING, WE NEED TO REINITIALIZE THE MODEL, OPTIMIZER AND SCHEDULER FOR A FAIR FIGHT. Rewrite below the changes you have brought to them.**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "hF-p2CCsNOVO"
+ },
+ "outputs": [],
+ "source": [
+ "model_optim = models.resnet18().to(args_optim['device'])\n",
+ "model_optim.name = 'Resnet-18'\n",
+ "optimizer_optim = torch.optim.SGD(model_optim.parameters(), args_optim['learning_rate'], args_optim['momentum'], args_optim['weight_decay'])\n",
+ "scheduler_optim = None"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "q79Y1wzENOVQ"
+ },
+ "outputs": [],
+ "source": [
+ "def train_optim(train_loader, val_loader, model, optimizer, criterion, args):\n",
+ " '''\n",
+ " The default simple training loop\n",
+ " '''\n",
+ " train_losses = []\n",
+ " train_accuracies = []\n",
+ " val_losses = []\n",
+ " val_accuracies = []\n",
+ " time_start = time.time()\n",
+ " for epoch in range(args['epochs']):\n",
+ " print(\"Epoch \", epoch)\n",
+ " for i, (images, labels) in enumerate(train_loader):\n",
+ " # distribution of images and labels to all GPUs\n",
+ " images = images.to(args['device'], non_blocking=True)\n",
+ " labels = labels.to(args['device'], non_blocking=True)\n",
+ " \n",
+ " # Zero the parameter gradients\n",
+ " optimizer.zero_grad()\n",
+ "\n",
+ " # Forward pass\n",
+ " outputs = model(images)\n",
+ " loss = criterion(outputs, labels)\n",
+ "\n",
+ " # Backward pass\n",
+ " loss.backward()\n",
+ "\n",
+ " # Optimize\n",
+ " optimizer.step()\n",
+ "\n",
+ " # Evaluate at the end of the epoch on the train set\n",
+ " train_loss, train_accuracy = evaluate(train_loader, model, criterion, args)\n",
+ " print(\"\\t Train loss : \", train_loss, \"& Train accuracy : \", train_accuracy)\n",
+ " train_losses.append(train_loss)\n",
+ " train_accuracies.append(train_accuracy) \n",
+ " \n",
+ " # Evaluate at the end of the epoch on the val set\n",
+ " val_loss, val_accuracy = evaluate(val_loader, model, criterion, args)\n",
+ " print(\"\\t Validation loss : \", val_loss, \"& Validation accuracy : \", val_accuracy)\n",
+ " val_losses.append(val_loss)\n",
+ " val_accuracies.append(val_accuracy)\n",
+ " duration = time.time() - time_start\n",
+ " print('Finished Training in:', duration, 'seconds with mean epoch duration:', duration/args['epochs'], ' seconds')\n",
+ " results = {'model':model,\n",
+ " 'train_losses': train_losses,\n",
+ " 'train_accuracies': train_accuracies,\n",
+ " 'val_losses': val_losses,\n",
+ " 'val_accuracies': val_accuracies,\n",
+ " 'duration':duration}\n",
+ " return results\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Z_T19pdUNOVR"
+ },
+ "source": [
+ "<details>\n",
+ "<summary>Spoiler</summary>\n",
+ " \n",
+ "```python\n",
+ "def train_optim(train_loader, val_loader, model, optimizer, criterion, scheduler, args):\n",
+ " '''\n",
+ " The default simple training loop\n",
+ " '''\n",
+ " train_losses = []\n",
+ " train_accuracies = []\n",
+ " val_losses = []\n",
+ " val_accuracies = []\n",
+ " time_start = time.time()\n",
+ " scaler = GradScaler()\n",
+ " for epoch in range(args['epochs']):\n",
+ " print(\"Epoch \", epoch)\n",
+ " for i, (images, labels) in enumerate(train_loader):\n",
+ " # distribution of images and labels to all GPUs\n",
+ " images = images.to(args['device'], non_blocking=True)\n",
+ " labels = labels.to(args['device'], non_blocking=True)\n",
+ " \n",
+ " # Zero the parameter gradients\n",
+ " optimizer.zero_grad()\n",
+ "\n",
+ " # Forward pass\n",
+ " with autocast():\n",
+ " outputs = model(images)\n",
+ " loss = criterion(outputs, labels)\n",
+ "\n",
+ " # Backward pass\n",
+ " scaler.scale(loss).backward()\n",
+ " \n",
+ " # Optimize\n",
+ " scaler.step(optimizer)\n",
+ " \n",
+ " # Updates the scale for next iteration.\n",
+ " scaler.update()\n",
+ " \n",
+ " # Update Learning Rate scheduler, warning some schedulers are updated every epoch and not step.\n",
+ " if scheduler is not None:\n",
+ " scheduler.step()\n",
+ "\n",
+ " # Evaluate at the end of the epoch\n",
+ " train_loss, train_accuracy = evaluate(train_loader, model, criterion, args)\n",
+ " print(\"\\t Train loss : \", train_loss, \"& Train accuracy : \", train_accuracy)\n",
+ " train_losses.append(train_loss)\n",
+ " train_accuracies.append(train_accuracy) \n",
+ " \n",
+ " # Evaluate at the end of the epoch\n",
+ " val_loss, val_accuracy = evaluate(val_loader, model, criterion, args)\n",
+ " print(\"\\t Validation loss : \", val_loss, \"& Validation accuracy : \", val_accuracy)\n",
+ " val_losses.append(val_loss)\n",
+ " val_accuracies.append(val_accuracy)\n",
+ " duration = time.time() - time_start\n",
+ " print('Finished Training in:', duration, 'seconds with mean epoch duration:', duration/args['epochs'], ' seconds')\n",
+ " results = {'model':model,\n",
+ " 'train_losses': train_losses,\n",
+ " 'train_accuracies': train_accuracies,\n",
+ " 'val_losses': val_losses,\n",
+ " 'val_accuracies': val_accuracies,\n",
+ " 'duration':duration}\n",
+ " return results\n",
+ "``` \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Xodf9IltNOVT"
+ },
+ "outputs": [],
+ "source": [
+ "results_optim = train_optim(train_loader_optim, val_loader_optim, model_optim, optimizer_optim, criterion_optim, args_optim)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MqMatOlMhO8X"
+ },
+ "source": [
+ "## Classification performances comparison\n",
+ "\n",
+ "> Take a look at\n",
+ ">- the loss and accuracy evolution\n",
+ ">- the difference in timings between the two runs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_ICf-vY3NOVU"
+ },
+ "outputs": [],
+ "source": [
+ "print(\"Duration for default setup training:\", results_default[\"duration\"])\n",
+ "print(\"Duration for optim setup training:\", results_optim[\"duration\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "upDC963kNOVV"
+ },
+ "outputs": [],
+ "source": [
+ "compare_trainings(results_default, results_optim)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "weOLNx69hQh6"
+ },
+ "source": [
+ "## Tensorboard\n",
+ "Below we added a profiler and a logger for tensorboard. If you want to do it yourself in future codes, you can take example on the following documentations::\n",
+ "- Pytorch : https://pytorch.org/tutorials/recipes/recipes/profiler_recipe.html\n",
+ "- IDRIS : http://www.idris.fr/jean-zay/pre-post/jean-zay-tensorboard.html\n",
+ "\n",
+ "> Try to add another metric to the logger, for example the validation loss at each epoch."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "0qRmXet6NOVW"
+ },
+ "outputs": [],
+ "source": [
+ "def train_default_tensorboard(train_loader, val_loader, model, optimizer, criterion, args, exp_name):\n",
+ " log_dir = \"./logs/\"+exp_name\n",
+ " writer = SummaryWriter(log_dir)\n",
+ " \n",
+ " train_losses = []\n",
+ " train_accuracies = []\n",
+ " val_losses = []\n",
+ " val_accuracies = []\n",
+ " time_start = time.time()\n",
+ " with torch.profiler.profile(\n",
+ " schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=2),\n",
+ " on_trace_ready=torch.profiler.tensorboard_trace_handler(log_dir),\n",
+ " record_shapes=True,\n",
+ " profile_memory=True,\n",
+ " with_stack=True\n",
+ " ) as prof:\n",
+ " for epoch in range(args['epochs']):\n",
+ " print(\"Epoch \", epoch)\n",
+ " for i, (images, labels) in enumerate(train_loader):\n",
+ " # distribution of images and labels to all GPUs\n",
+ " images = images.to(args['device'], non_blocking=True)\n",
+ " labels = labels.to(args['device'], non_blocking=True)\n",
+ "\n",
+ " # Zero the parameter gradients\n",
+ " optimizer.zero_grad()\n",
+ "\n",
+ " # Forward pass\n",
+ " outputs = model(images)\n",
+ " loss = criterion(outputs, labels)\n",
+ " \n",
+ " # Log a scalar (loss)\n",
+ " writer.add_scalar(\"Loss/train\", loss, i+epoch*len(train_loader))\n",
+ " \n",
+ " # Backward pass\n",
+ " loss.backward()\n",
+ "\n",
+ " # Optimize\n",
+ " optimizer.step()\n",
+ " \n",
+ " # Indicate to profiler when a step is over\n",
+ " prof.step()\n",
+ " \n",
+ " # Evaluate at the end of the epoch on the train set\n",
+ " train_loss, train_accuracy = evaluate(train_loader, model, criterion, args)\n",
+ " print(\"\\t Train loss : \", train_loss, \"& Train accuracy : \", train_accuracy)\n",
+ " train_losses.append(train_loss)\n",
+ " train_accuracies.append(train_accuracy) \n",
+ "\n",
+ " # Evaluate at the end of the epoch on the val set\n",
+ " val_loss, val_accuracy = evaluate(val_loader, model, criterion, args)\n",
+ " print(\"\\t Validation loss : \", val_loss, \"& Validation accuracy : \", val_accuracy)\n",
+ " val_losses.append(val_loss)\n",
+ " val_accuracies.append(val_accuracy)\n",
+ " duration = time.time() - time_start\n",
+ " print('Finished Training in:', duration, 'seconds with mean epoch duration:', duration/args['epochs'], ' seconds')\n",
+ " results = {'model':model,\n",
+ " 'train_losses': train_losses,\n",
+ " 'train_accuracies': train_accuracies,\n",
+ " 'val_losses': val_losses,\n",
+ " 'val_accuracies': val_accuracies,\n",
+ " 'duration':duration}\n",
+ " return results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "mAPz5qdYNOVX"
+ },
+ "outputs": [],
+ "source": [
+ "args[\"epochs\"] = 1\n",
+ "_ = train_default_tensorboard(train_loader, val_loader, model, optimizer, criterion, args, \"default_perf\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "VlUFsWoVNOVa"
+ },
+ "outputs": [],
+ "source": [
+ "# Load the TensorBoard notebook extension\n",
+ "!pip install torch_tb_profiler\n",
+ "%load_ext tensorboard\n",
+ "%tensorboard --logdir logs"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "provenance": []
+ },
+ "gpuClass": "standard",
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/README.ipynb b/README.ipynb
index 962b9c14fee42d82ac9a2b2a061d02ee0f4e3eaa..2ed8a2b61a068da9a58d223e25bb4d27df152819 100644
--- a/README.ipynb
+++ b/README.ipynb
@@ -3,13 +3,13 @@
{
"cell_type": "code",
"execution_count": 1,
- "id": "916506c0",
+ "id": "c36f1d62",
"metadata": {
"execution": {
- "iopub.execute_input": "2022-12-19T09:48:07.260059Z",
- "iopub.status.busy": "2022-12-19T09:48:07.259179Z",
- "iopub.status.idle": "2022-12-19T09:48:07.274680Z",
- "shell.execute_reply": "2022-12-19T09:48:07.273954Z"
+ "iopub.execute_input": "2023-04-12T07:28:58.304935Z",
+ "iopub.status.busy": "2023-04-12T07:28:58.304172Z",
+ "iopub.status.idle": "2023-04-12T07:28:58.313981Z",
+ "shell.execute_reply": "2023-04-12T07:28:58.313154Z"
},
"jupyter": {
"source_hidden": true
@@ -52,7 +52,7 @@
"For more information, you can contact us at : \n",
"[<img width=\"200px\" style=\"vertical-align:middle\" src=\"fidle/img/00-Mail_contact.svg\"></img>](#top)\n",
"\n",
- "Current Version : <!-- VERSION_BEGIN -->2.2.3<!-- VERSION_END -->\n",
+ "Current Version : <!-- VERSION_BEGIN -->2.2.4<!-- VERSION_END -->\n",
"\n",
"\n",
"## Course materials\n",
@@ -67,7 +67,7 @@
"## Jupyter notebooks\n",
"\n",
"<!-- TOC_BEGIN -->\n",
- "<!-- Automatically generated on : 19/12/22 10:48:06 -->\n",
+ "<!-- Automatically generated on : 12/04/23 09:28:57 -->\n",
"\n",
"### Linear and logistic regression\n",
"- **[LINR1](LinearReg/01-Linear-Regression.ipynb)** - [Linear regression with direct resolution](LinearReg/01-Linear-Regression.ipynb) \n",
@@ -97,7 +97,7 @@
"- **[MNIST2](MNIST/02-CNN-MNIST.ipynb)** - [Simple classification with CNN](MNIST/02-CNN-MNIST.ipynb) \n",
"An example of classification using a convolutional neural network for the famous MNIST dataset\n",
"\n",
- "### Images classification with Convolutional Neural Networks (CNN\n",
+ "### Images classification with Convolutional Neural Networks (CNN)\n",
"- **[GTSRB1](GTSRB/01-Preparation-of-data.ipynb)** - [Dataset analysis and preparation](GTSRB/01-Preparation-of-data.ipynb) \n",
"Episode 1 : Analysis of the GTSRB dataset and creation of an enhanced dataset\n",
"- **[GTSRB2](GTSRB/02-First-convolutions.ipynb)** - [First convolutions](GTSRB/02-First-convolutions.ipynb) \n",
@@ -129,7 +129,7 @@
"- **[IMDB5](IMDB/05-LSTM-Keras.ipynb)** - [Sentiment analysis with a RNN network](IMDB/05-LSTM-Keras.ipynb) \n",
"Still the same problem, but with a network combining embedding and RNN\n",
"\n",
- "### Time series with Recurrent Neural Network (RNN\n",
+ "### Time series with Recurrent Neural Network (RNN)\n",
"- **[LADYB1](SYNOP/LADYB1-Ladybug.ipynb)** - [Prediction of a 2D trajectory via RNN](SYNOP/LADYB1-Ladybug.ipynb) \n",
"Artificial dataset generation and prediction attempt via a recurrent network\n",
"- **[SYNOP1](SYNOP/SYNOP1-Preparation-of-data.ipynb)** - [Preparation of data](SYNOP/SYNOP1-Preparation-of-data.ipynb) \n",
@@ -145,7 +145,7 @@
"- **[TRANS2](Transformers/02-distilbert_colab.ipynb)** - [IMDB, Sentiment analysis with Transformers ](Transformers/02-distilbert_colab.ipynb) \n",
"Using a Tranformer to perform a sentiment analysis (IMDB) - Colab version\n",
"\n",
- "### Unsupervised learning with an autoencoder neural network (AE\n",
+ "### Unsupervised learning with an autoencoder neural network (AE)\n",
"- **[AE1](AE/01-Prepare-MNIST-dataset.ipynb)** - [Prepare a noisy MNIST dataset](AE/01-Prepare-MNIST-dataset.ipynb) \n",
"Episode 1: Preparation of a noisy MNIST dataset\n",
"- **[AE2](AE/02-AE-with-MNIST.ipynb)** - [Building and training an AE denoiser model](AE/02-AE-with-MNIST.ipynb) \n",
@@ -157,35 +157,31 @@
"- **[AE5](AE/05-ExtAE-with-MNIST.ipynb)** - [Advanced denoiser and classifier model](AE/05-ExtAE-with-MNIST.ipynb) \n",
"Episode 5 : Construction of an advanced denoiser and classifier model\n",
"\n",
- "### Generative network with Variational Autoencoder (VAE\n",
+ "### Generative network with Variational Autoencoder (VAE)\n",
"- **[VAE1](VAE/01-VAE-with-MNIST.ipynb)** - [First VAE, using functional API (MNIST dataset)](VAE/01-VAE-with-MNIST.ipynb) \n",
"Construction and training of a VAE, using functional APPI, with a latent space of small dimension.\n",
"- **[VAE2](VAE/02-VAE-with-MNIST.ipynb)** - [VAE, using a custom model class (MNIST dataset)](VAE/02-VAE-with-MNIST.ipynb) \n",
"Construction and training of a VAE, using model subclass, with a latent space of small dimension.\n",
"- **[VAE3](VAE/03-VAE-with-MNIST-post.ipynb)** - [Analysis of the VAE's latent space of MNIST dataset](VAE/03-VAE-with-MNIST-post.ipynb) \n",
"Visualization and analysis of the VAE's latent space of the dataset MNIST\n",
- "- **[VAE5](VAE/05-About-CelebA.ipynb)** - [Another game play : About the CelebA dataset](VAE/05-About-CelebA.ipynb) \n",
- "Episode 1 : Presentation of the CelebA dataset and problems related to its size\n",
- "- **[VAE6](VAE/06-Prepare-CelebA-datasets.ipynb)** - [Generation of a clustered dataset](VAE/06-Prepare-CelebA-datasets.ipynb) \n",
- "Episode 2 : Analysis of the CelebA dataset and creation of an clustered and usable dataset\n",
- "- **[VAE7](VAE/07-Check-CelebA.ipynb)** - [Checking the clustered dataset](VAE/07-Check-CelebA.ipynb) \n",
- "Episode : 3 Clustered dataset verification and testing of our datagenerator\n",
- "- **[VAE8](VAE/08-VAE-with-CelebA-128x128.ipynb)** - [Training session for our VAE with 128x128 images](VAE/08-VAE-with-CelebA-128x128.ipynb) \n",
- "Episode 4 : Training with our clustered datasets in notebook or batch mode\n",
- "- **[VAE9](VAE/09-VAE-with-CelebA-192x160.ipynb)** - [Training session for our VAE with 192x160 images](VAE/09-VAE-with-CelebA-192x160.ipynb) \n",
- "Episode 4 : Training with our clustered datasets in notebook or batch mode\n",
- "- **[VAE10](VAE/10-VAE-with-CelebA-post.ipynb)** - [Data generation from latent space](VAE/10-VAE-with-CelebA-post.ipynb) \n",
- "Episode 5 : Exploring latent space to generate new data\n",
- "- **[VAE10](VAE/batch_slurm.sh)** - [SLURM batch script](VAE/batch_slurm.sh) \n",
- "Bash script for SLURM batch submission of VAE8 notebooks \n",
- "\n",
- "### Generative Adversarial Networks (GANs\n",
+ "\n",
+ "### Generative Adversarial Networks (GANs)\n",
"- **[SHEEP1](DCGAN/01-DCGAN-Draw-me-a-sheep.ipynb)** - [A first DCGAN to Draw a Sheep](DCGAN/01-DCGAN-Draw-me-a-sheep.ipynb) \n",
"Episode 1 : Draw me a sheep, revisited with a DCGAN\n",
"- **[SHEEP2](DCGAN/02-WGANGP-Draw-me-a-sheep.ipynb)** - [A WGAN-GP to Draw a Sheep](DCGAN/02-WGANGP-Draw-me-a-sheep.ipynb) \n",
"Episode 2 : Draw me a sheep, revisited with a WGAN-GP\n",
"\n",
- "### Deep Reinforcement Learning (DRL\n",
+ "### Diffusion Model (DDPM)\n",
+ "- **[DDPM1](DDPM/01-ddpm.ipynb)** - [Fashion MNIST Generation with DDPM](DDPM/01-ddpm.ipynb) \n",
+ "Diffusion Model example, to generate Fashion MNIST images.\n",
+ "- **[DDPM2](DDPM/model.py)** - [DDPM Python classes](DDPM/model.py) \n",
+ "Python classes used by DDMP Example\n",
+ "\n",
+ "### Training optimization\n",
+ "- **[OPT1](Optimization/01-Apprentissages-rapides-et-Optimisations.ipynb)** - [Training setup optimization](Optimization/01-Apprentissages-rapides-et-Optimisations.ipynb) \n",
+ "The goal of this notebook is to go through a typical deep learning model training\n",
+ "\n",
+ "### Deep Reinforcement Learning (DRL)\n",
"- **[DRL1](DRL/FIDLE_DQNfromScratch.ipynb)** - [Solving CartPole with DQN](DRL/FIDLE_DQNfromScratch.ipynb) \n",
"Using a a Deep Q-Network to play CartPole - an inverted pendulum problem (PyTorch)\n",
"- **[DRL2](DRL/FIDLE_rl_baselines_zoo.ipynb)** - [RL Baselines3 Zoo: Training in Colab](DRL/FIDLE_rl_baselines_zoo.ipynb) \n",
@@ -233,7 +229,7 @@
"from IPython.display import display,Markdown\n",
"display(Markdown(open('README.md', 'r').read()))\n",
"#\n",
- "# This README is visible under Jupiter Lab ;-)# Automatically generated on : 19/12/22 10:48:06"
+ "# This README is visible under Jupiter Lab ;-)# Automatically generated on : 12/04/23 09:28:57"
]
}
],
diff --git a/README.md b/README.md
index 4ae66bb7e198ce29204fe80d1ddf843a9e0c3e58..48da9b1f313a37ba225486b590e4ef318aef9832 100644
--- a/README.md
+++ b/README.md
@@ -31,7 +31,7 @@ For more information, see **https://fidle.cnrs.fr** :
For more information, you can contact us at :
[<img width="200px" style="vertical-align:middle" src="fidle/img/00-Mail_contact.svg"></img>](#top)
-Current Version : <!-- VERSION_BEGIN -->2.2.3<!-- VERSION_END -->
+Current Version : <!-- VERSION_BEGIN -->2.2.4<!-- VERSION_END -->
## Course materials
@@ -46,7 +46,7 @@ Have a look about **[How to get and install](https://fidle.cnrs.fr/installation)
## Jupyter notebooks
<!-- TOC_BEGIN -->
-<!-- Automatically generated on : 19/12/22 10:48:06 -->
+<!-- Automatically generated on : 12/04/23 09:28:57 -->
### Linear and logistic regression
- **[LINR1](LinearReg/01-Linear-Regression.ipynb)** - [Linear regression with direct resolution](LinearReg/01-Linear-Regression.ipynb)
@@ -76,7 +76,7 @@ An example of classification using a dense neural network for the famous MNIST d
- **[MNIST2](MNIST/02-CNN-MNIST.ipynb)** - [Simple classification with CNN](MNIST/02-CNN-MNIST.ipynb)
An example of classification using a convolutional neural network for the famous MNIST dataset
-### Images classification with Convolutional Neural Networks (CNN
+### Images classification with Convolutional Neural Networks (CNN)
- **[GTSRB1](GTSRB/01-Preparation-of-data.ipynb)** - [Dataset analysis and preparation](GTSRB/01-Preparation-of-data.ipynb)
Episode 1 : Analysis of the GTSRB dataset and creation of an enhanced dataset
- **[GTSRB2](GTSRB/02-First-convolutions.ipynb)** - [First convolutions](GTSRB/02-First-convolutions.ipynb)
@@ -96,7 +96,7 @@ Bash script for an OAR batch submission of an ipython code
- **[GTSRB11](GTSRB/batch_slurm.sh)** - [SLURM batch script](GTSRB/batch_slurm.sh)
Bash script for a Slurm batch submission of an ipython code
-### Sentiment analysis with word embedding
+### Sentiment analysis with word embeddin
- **[IMDB1](IMDB/01-One-hot-encoding.ipynb)** - [Sentiment analysis with hot-one encoding](IMDB/01-One-hot-encoding.ipynb)
A basic example of sentiment analysis with sparse encoding, using a dataset from Internet Movie Database (IMDB)
- **[IMDB2](IMDB/02-Keras-embedding.ipynb)** - [Sentiment analysis with text embedding](IMDB/02-Keras-embedding.ipynb)
@@ -108,7 +108,7 @@ Retrieving embedded vectors from our trained model
- **[IMDB5](IMDB/05-LSTM-Keras.ipynb)** - [Sentiment analysis with a RNN network](IMDB/05-LSTM-Keras.ipynb)
Still the same problem, but with a network combining embedding and RNN
-### Time series with Recurrent Neural Network (RNN
+### Time series with Recurrent Neural Network (RNN)
- **[LADYB1](SYNOP/LADYB1-Ladybug.ipynb)** - [Prediction of a 2D trajectory via RNN](SYNOP/LADYB1-Ladybug.ipynb)
Artificial dataset generation and prediction attempt via a recurrent network
- **[SYNOP1](SYNOP/SYNOP1-Preparation-of-data.ipynb)** - [Preparation of data](SYNOP/SYNOP1-Preparation-of-data.ipynb)
@@ -124,7 +124,7 @@ Using a Tranformer to perform a sentiment analysis (IMDB) - Jean Zay version
- **[TRANS2](Transformers/02-distilbert_colab.ipynb)** - [IMDB, Sentiment analysis with Transformers ](Transformers/02-distilbert_colab.ipynb)
Using a Tranformer to perform a sentiment analysis (IMDB) - Colab version
-### Unsupervised learning with an autoencoder neural network (AE
+### Unsupervised learning with an autoencoder neural network (AE)
- **[AE1](AE/01-Prepare-MNIST-dataset.ipynb)** - [Prepare a noisy MNIST dataset](AE/01-Prepare-MNIST-dataset.ipynb)
Episode 1: Preparation of a noisy MNIST dataset
- **[AE2](AE/02-AE-with-MNIST.ipynb)** - [Building and training an AE denoiser model](AE/02-AE-with-MNIST.ipynb)
@@ -136,35 +136,31 @@ Episode 4 : Construction of a denoiser and classifier model
- **[AE5](AE/05-ExtAE-with-MNIST.ipynb)** - [Advanced denoiser and classifier model](AE/05-ExtAE-with-MNIST.ipynb)
Episode 5 : Construction of an advanced denoiser and classifier model
-### Generative network with Variational Autoencoder (VAE
+### Generative network with Variational Autoencoder (VAE)
- **[VAE1](VAE/01-VAE-with-MNIST.ipynb)** - [First VAE, using functional API (MNIST dataset)](VAE/01-VAE-with-MNIST.ipynb)
Construction and training of a VAE, using functional APPI, with a latent space of small dimension.
- **[VAE2](VAE/02-VAE-with-MNIST.ipynb)** - [VAE, using a custom model class (MNIST dataset)](VAE/02-VAE-with-MNIST.ipynb)
Construction and training of a VAE, using model subclass, with a latent space of small dimension.
- **[VAE3](VAE/03-VAE-with-MNIST-post.ipynb)** - [Analysis of the VAE's latent space of MNIST dataset](VAE/03-VAE-with-MNIST-post.ipynb)
Visualization and analysis of the VAE's latent space of the dataset MNIST
-- **[VAE5](VAE/05-About-CelebA.ipynb)** - [Another game play : About the CelebA dataset](VAE/05-About-CelebA.ipynb)
-Episode 1 : Presentation of the CelebA dataset and problems related to its size
-- **[VAE6](VAE/06-Prepare-CelebA-datasets.ipynb)** - [Generation of a clustered dataset](VAE/06-Prepare-CelebA-datasets.ipynb)
-Episode 2 : Analysis of the CelebA dataset and creation of an clustered and usable dataset
-- **[VAE7](VAE/07-Check-CelebA.ipynb)** - [Checking the clustered dataset](VAE/07-Check-CelebA.ipynb)
-Episode : 3 Clustered dataset verification and testing of our datagenerator
-- **[VAE8](VAE/08-VAE-with-CelebA-128x128.ipynb)** - [Training session for our VAE with 128x128 images](VAE/08-VAE-with-CelebA-128x128.ipynb)
-Episode 4 : Training with our clustered datasets in notebook or batch mode
-- **[VAE9](VAE/09-VAE-with-CelebA-192x160.ipynb)** - [Training session for our VAE with 192x160 images](VAE/09-VAE-with-CelebA-192x160.ipynb)
-Episode 4 : Training with our clustered datasets in notebook or batch mode
-- **[VAE10](VAE/10-VAE-with-CelebA-post.ipynb)** - [Data generation from latent space](VAE/10-VAE-with-CelebA-post.ipynb)
-Episode 5 : Exploring latent space to generate new data
-- **[VAE10](VAE/batch_slurm.sh)** - [SLURM batch script](VAE/batch_slurm.sh)
-Bash script for SLURM batch submission of VAE8 notebooks
-
-### Generative Adversarial Networks (GANs
+
+### Generative Adversarial Networks (GANs)
- **[SHEEP1](DCGAN/01-DCGAN-Draw-me-a-sheep.ipynb)** - [A first DCGAN to Draw a Sheep](DCGAN/01-DCGAN-Draw-me-a-sheep.ipynb)
Episode 1 : Draw me a sheep, revisited with a DCGAN
- **[SHEEP2](DCGAN/02-WGANGP-Draw-me-a-sheep.ipynb)** - [A WGAN-GP to Draw a Sheep](DCGAN/02-WGANGP-Draw-me-a-sheep.ipynb)
Episode 2 : Draw me a sheep, revisited with a WGAN-GP
-### Deep Reinforcement Learning (DRL
+### Diffusion Model (DDPM)
+- **[DDPM1](DDPM/01-ddpm.ipynb)** - [Fashion MNIST Generation with DDPM](DDPM/01-ddpm.ipynb)
+Diffusion Model example, to generate Fashion MNIST images.
+- **[DDPM2](DDPM/model.py)** - [DDPM Python classes](DDPM/model.py)
+Python classes used by DDMP Example
+
+### Training optimization
+- **[OPT1](Optimization/01-Apprentissages-rapides-et-Optimisations.ipynb)** - [Training setup optimization](Optimization/01-Apprentissages-rapides-et-Optimisations.ipynb)
+The goal of this notebook is to go through a typical deep learning model training
+
+### Deep Reinforcement Learning (DRL)
- **[DRL1](DRL/FIDLE_DQNfromScratch.ipynb)** - [Solving CartPole with DQN](DRL/FIDLE_DQNfromScratch.ipynb)
Using a a Deep Q-Network to play CartPole - an inverted pendulum problem (PyTorch)
- **[DRL2](DRL/FIDLE_rl_baselines_zoo.ipynb)** - [RL Baselines3 Zoo: Training in Colab](DRL/FIDLE_rl_baselines_zoo.ipynb)
diff --git a/VAE/05-About-CelebA.ipynb b/VAE/05-About-CelebA.ipynb
deleted file mode 100644
index 752926fab043f16df5e62f2255ce7033c7bbc2a9..0000000000000000000000000000000000000000
--- a/VAE/05-About-CelebA.ipynb
+++ /dev/null
@@ -1,267 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
- "\n",
- "# <!-- TITLE --> [VAE5] - Another game play : About the CelebA dataset\n",
- "<!-- DESC --> Episode 1 : Presentation of the CelebA dataset and problems related to its size\n",
- "<!-- AUTHOR : Jean-Luc Parouty (CNRS/SIMaP) -->\n",
- "\n",
- "## Objectives :\n",
- " - Data **analysis**\n",
- " - Problems related to the use of **more real datasets**\n",
- "\n",
- "We'll do the same thing again but with a more interesting dataset: **CelebFaces** \n",
- "\"[CelebFaces Attributes Dataset (CelebA)](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations.\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 1 - Import and init"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import matplotlib.pyplot as plt\n",
- "import pandas as pd\n",
- "from skimage import io, transform\n",
- "\n",
- "import os,time,sys,json,glob\n",
- "import csv\n",
- "import math, random\n",
- "\n",
- "from importlib import reload\n",
- "\n",
- "import fidle\n",
- "\n",
- "# Init Fidle environment\n",
- "run_id, run_dir, datasets_dir = fidle.init('VAE5')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "`progress_verbosity`: Verbosity of progress bar: 0=silent, 1=progress bar, 2=One line"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "progress_verbosity = 1"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Override parameters (batch mode) - Just forget this cell"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.override('progress_verbosity')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 2 - Understanding the dataset"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 2.1 - Read the catalog file"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "dataset_csv = f'{datasets_dir}/celeba/origine/list_attr_celeba.csv'\n",
- "dataset_img = f'{datasets_dir}/celeba/origine/img_align_celeba'\n",
- "\n",
- "# ---- Read dataset attributes\n",
- "\n",
- "dataset_desc = pd.read_csv(dataset_csv, header=0)\n",
- "\n",
- "# ---- Have a look\n",
- "\n",
- "display(dataset_desc.head(10))\n",
- "\n",
- "print(f'\\nDonnées manquantes : {dataset_desc.isna().sum().sum()}')\n",
- "print(f'dataset_desc.shape : {dataset_desc.shape}')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 2.2 - Load 1000 images"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "chrono = fidle.Chrono()\n",
- "chrono.start()\n",
- "\n",
- "nb_images=5000\n",
- "filenames = [ f'{dataset_img}/{i}' for i in dataset_desc.image_id[:nb_images] ]\n",
- "x=[]\n",
- "for filename in filenames:\n",
- " image=io.imread(filename)\n",
- " x.append(image)\n",
- " fidle.utils.update_progress(f\"{nb_images} images :\",len(x),nb_images, verbosity=progress_verbosity)\n",
- "x_data=np.array(x)\n",
- "x=None\n",
- " \n",
- "duration=chrono.get_delay(format='seconds')\n",
- "print(f'\\nDuration : {duration} s')\n",
- "print(f'Shape is : {x_data.shape}')\n",
- "print(f'Numpy type : {x_data.dtype}')\n",
- "\n",
- "fidle.utils.display_md('<br>**Note :** Estimation for **200.000** normalized images : ')\n",
- "x_data=x_data/255\n",
- "k=200000/nb_images\n",
- "print(f'Charging time : {k*duration:.2f} s or {fidle.utils.hdelay(k*duration)}')\n",
- "print(f'Numpy type : {x_data.dtype}')\n",
- "print(f'Memory size : {fidle.utils.hsize(k*x_data.nbytes)}')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 3 - Have a look\n",
- "\n",
- "### 3.1 - Few statistics\n",
- "We want to know if our images are homogeneous in terms of size, ratio, width or height."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "data_size = []\n",
- "data_ratio = []\n",
- "data_lx = []\n",
- "data_ly = []\n",
- "\n",
- "for image in x_data:\n",
- " (lx,ly,lz) = image.shape\n",
- " data_size.append(lx*ly/1024)\n",
- " data_ratio.append(lx/ly)\n",
- " data_lx.append(lx)\n",
- " data_ly.append(ly)\n",
- "\n",
- "df=pd.DataFrame({'Size':data_size, 'Ratio':data_ratio, 'Lx':data_lx, 'Ly':data_ly})\n",
- "display(df.describe().style.format(\"{0:.2f}\").set_caption(\"About our images :\"))\n",
- " "
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 3.2 - What does it really look like"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "samples = [ random.randint(0,len(x_data)-1) for i in range(32)]\n",
- "fidle.scrawler.images(x_data, indices=samples, columns=8, x_size=2, y_size=2, save_as='01-celebA')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## AAArrrg !!\n",
- "Fine ! :-) \n",
- "But how can we effectively use this dataset, considering its size and the number of files ? \n",
- "We're talking about a **10' to 20' of loading time** and **170 GB of data**... ;-( \n",
- "\n",
- "The only solution will be to:\n",
- "- group images into clusters, to limit the number of files,\n",
- "- read the data gradually, because not all of it can be stored in memory\n",
- "\n",
- "Welcome in the real world ;-)\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "---\n",
- "<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3.9.2 ('fidle-env')",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.2"
- },
- "vscode": {
- "interpreter": {
- "hash": "b3929042cc22c1274d74e3e946c52b845b57cb6d84f2d591ffe0519b38e4896d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/VAE/06-Prepare-CelebA-datasets.ipynb b/VAE/06-Prepare-CelebA-datasets.ipynb
deleted file mode 100644
index bb6b9b64e95c4a2e7581b33b6f1bce2d5232e009..0000000000000000000000000000000000000000
--- a/VAE/06-Prepare-CelebA-datasets.ipynb
+++ /dev/null
@@ -1,377 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
- "\n",
- "# <!-- TITLE --> [VAE6] - Generation of a clustered dataset\n",
- "<!-- DESC --> Episode 2 : Analysis of the CelebA dataset and creation of an clustered and usable dataset\n",
- "<!-- AUTHOR : Jean-Luc Parouty (CNRS/SIMaP) -->\n",
- "\n",
- "## Objectives :\n",
- " - Formatting our dataset in **cluster files**, using batch mode\n",
- " - Adapting a notebook for batch use\n",
- "\n",
- "\n",
- "The [CelebFaces Attributes Dataset (CelebA)](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) contains about **200,000 images** (202599,218,178,3). \n",
- "The size and the number of files of this dataset make it impossible to use it as it is. \n",
- "A formatting in the form of clusters of n images is essential.\n",
- "\n",
- "\n",
- "## What we're going to do :\n",
- " - Lire les images\n",
- " - redimensionner et normaliser celles-ci,\n",
- " - Constituer des clusters d'images en format npy\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 1 - Import and init"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import matplotlib.pyplot as plt\n",
- "import pandas as pd\n",
- "from skimage import io, transform\n",
- "\n",
- "import os,pathlib,time,sys,json,glob\n",
- "import csv\n",
- "import math, random\n",
- "\n",
- "import fidle\n",
- "\n",
- "# Init Fidle environment\n",
- "run_id, run_dir, datasets_dir = fidle.init('VAE6')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 2 - Parameters\n",
- "All the dataset will be use for training \n",
- "Reading the 200,000 images can take a long time **(>20 minutes)** and a lot of place **(>170 GB)** \n",
- "Example : \n",
- "Image Sizes: 128x128 : 74 GB \n",
- "Image Sizes: 192x160 : 138 GB \n",
- "\n",
- "You can define theses parameters : \n",
- "`scale` : 1 mean 100% of the dataset - set 0.05 for tests \n",
- "`image_size` : images size in the clusters, should be 128x128 or 192,160 - original size is (218,178) \n",
- "`output_dir` : where to write clusters, could be :\n",
- " - `./data`, for tests purpose\n",
- " - `<datasets_dir>/celeba/enhanced` to add clusters in your datasets dir. \n",
- " \n",
- "`cluster_size` : number of images in a cluster, 10000 is fine. (will be adjust by scale) \n",
- "`progress_verbosity`: Verbosity of progress bar: 0=silent, 1=progress bar, 2=One line \n",
- "\n",
- "**Note :** If the target folder is not empty and exit_if_exist is True, the construction is blocked. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- Parameters you can change -----------------------------------\n",
- "#\n",
- "progress_verbosity = 1\n",
- "\n",
- "# ---- Just for tests\n",
- "# Save clustered dataset in ./data\n",
- "#\n",
- "scale = 0.05\n",
- "seed = 123\n",
- "cluster_size = 10000\n",
- "image_size = (128,128)\n",
- "output_dir = './data'\n",
- "exit_if_exist = False\n",
- "\n",
- "# ---- Full clusters generation, medium size : 74 GB\n",
- "# Save clustered dataset in <datasets_dir> \n",
- "#\n",
- "# scale = 1.\n",
- "# seed = 123\n",
- "# cluster_size = 10000\n",
- "# image_size = (128,128)\n",
- "# output_dir = f'{datasets_dir}/celeba/enhanced'\n",
- "# exit_if_exist = True\n",
- "\n",
- "# ---- Just for tests\n",
- "# Save clustered dataset in ./data\n",
- "#\n",
- "# scale = 0.05\n",
- "# seed = 123\n",
- "# cluster_size = 10000\n",
- "# image_size = (192,160)\n",
- "# output_dir = './data'\n",
- "# exit_if_exist = False\n",
- "\n",
- "# ---- Full clusters generation, large size : 138 GB\n",
- "# Save clustered dataset in <datasets_dir> \n",
- "#\n",
- "# scale = 1.\n",
- "# seed = 123\n",
- "# cluster_size = 10000\n",
- "# image_size = (192,160)\n",
- "# output_dir = f'{datasets_dir}/celeba/enhanced'\n",
- "# exit_if_exist = True"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- Used for continous integration - Just forget these lines\n",
- "#\n",
- "fidle.override('progress_verbosity', 'scale', 'seed', )\n",
- "fidle.override('cluster_size', 'image_size', 'output_dir', 'exit_if_exist')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 3 - Cluster construction"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 3.1 - Directories and files :"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "dataset_csv = f'{datasets_dir}/celeba/origine/list_attr_celeba.csv'\n",
- "dataset_img = f'{datasets_dir}/celeba/origine/img_align_celeba'"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 3.2 - Cooking function"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "def read_and_save( dataset_csv, dataset_img, shuffle=True, seed=None, scale=1,\n",
- " cluster_size=1000, cluster_dir='./dataset_cluster', cluster_name='images',\n",
- " image_size=(128,128), exit_if_exist=True, verbosity=1):\n",
- " '''\n",
- " Will read the images and save a clustered dataset\n",
- "\n",
- " Args:\n",
- " dataset_csv : list and description of original images\n",
- " dataset_img : original images directory\n",
- " shuffle : shuffle data if True (True)\n",
- " seed : random seed value. False mean no seed, None mean using /dev/urandom (None)\n",
- " scale : scale of dataset to use. 1. mean 100% (1.)\n",
- " cluster_size : Size of generated cluster (10000)\n",
- " cluster_dir : Directory of generated clusters (''./dataset_cluster')\n",
- " cluster_name : Name of generated clusters ('images')\n",
- " image_size : Size of generated images (128,128)\n",
- " exit_if_exist : Exit if clusters still exists.\n",
- "\n",
- " Returns:\n",
- " nb_clusters : Number of clusters\n",
- " duration: total duration\n",
- " '''\n",
- "\n",
- " def save_cluster(imgs,desc,cols,id):\n",
- " file_img = f'{cluster_dir}/{cluster_name}-{id:03d}.npy'\n",
- " file_desc = f'{cluster_dir}/{cluster_name}-{id:03d}.csv'\n",
- " np.save(file_img, np.array(imgs))\n",
- " df=pd.DataFrame(data=desc,columns=cols)\n",
- " df.to_csv(file_desc, index=False)\n",
- " return [],[],id+1\n",
- " \n",
- " chrono = fidle.Chrono()\n",
- " chrono.start()\n",
- " \n",
- " # ---- Seed\n",
- " #\n",
- " if seed is not False:\n",
- " np.random.seed(seed)\n",
- " print(f'Seeded ({seed})')\n",
- " \n",
- " # ---- Read dataset description\n",
- " #\n",
- " dataset_desc = pd.read_csv(dataset_csv, header=0)\n",
- " n=len(dataset_desc)\n",
- " print(f'Description loaded ({n} images).')\n",
- " \n",
- " # ---- Shuffle\n",
- " #\n",
- " if shuffle:\n",
- " dataset_desc = dataset_desc.reindex(np.random.permutation(dataset_desc.index))\n",
- " print('Shuffled.')\n",
- " cols = list(dataset_desc.columns)\n",
- "\n",
- " # ---- Check if cluster files exist\n",
- " #\n",
- " if exit_if_exist and os.path.isfile(f'{cluster_dir}/images-000.npy'):\n",
- " print('\\n*** Oups. There are already clusters in the target folder!\\n')\n",
- " return 0,0\n",
- " fidle.utils.mkdir(cluster_dir)\n",
- "\n",
- " # ---- Rescale\n",
- " #\n",
- " n=int(len(dataset_desc)*scale)\n",
- " dataset = dataset_desc[:n]\n",
- " cluster_size = int(cluster_size*scale)\n",
- " print('Rescaled.')\n",
- " fidle.utils.subtitle('Parameters :')\n",
- " print(f'Scale is : {scale}')\n",
- " print(f'Image size is : {image_size}')\n",
- " print(f'dataset length is : {n}')\n",
- " print(f'cluster size is : {cluster_size}')\n",
- " print(f'clusters nb is :',int(n/cluster_size + 1))\n",
- " print(f'cluster dir is : {cluster_dir}')\n",
- " \n",
- " # ---- Read and save clusters\n",
- " #\n",
- " fidle.utils.subtitle('Running...')\n",
- " imgs, desc, cluster_id = [],[],0\n",
- " #\n",
- " for i,row in dataset.iterrows():\n",
- " #\n",
- " filename = f'{dataset_img}/{row.image_id}'\n",
- " #\n",
- " # ---- Read image, resize (and normalize)\n",
- " #\n",
- " img = io.imread(filename)\n",
- " img = transform.resize(img, image_size)\n",
- " #\n",
- " # ---- Add image and description\n",
- " #\n",
- " imgs.append( img )\n",
- " desc.append( row.values )\n",
- " #\n",
- " # ---- Progress bar\n",
- " #\n",
- " fidle.utils.update_progress(f'Cluster {cluster_id:03d} :',len(imgs),\n",
- " cluster_size, verbosity=verbosity)\n",
- " #\n",
- " # ---- Save cluster if full\n",
- " #\n",
- " if len(imgs)==cluster_size:\n",
- " imgs,desc,cluster_id=save_cluster(imgs,desc,cols, cluster_id)\n",
- "\n",
- " # ---- Save uncomplete cluster\n",
- " if len(imgs)>0 : imgs,desc,cluster_id=save_cluster(imgs,desc,cols,cluster_id)\n",
- "\n",
- " duration=chrono.get_delay(format='seconds')\n",
- " return cluster_id,duration\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 3.3 - Clusters building"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- Build clusters\n",
- "#\n",
- "lx,ly = image_size\n",
- "cluster_dir = f'{output_dir}/clusters-{lx}x{ly}'\n",
- "\n",
- "cluster_nb,duration = read_and_save( dataset_csv, dataset_img,\n",
- " shuffle = True,\n",
- " seed = seed,\n",
- " scale = scale,\n",
- " cluster_size = cluster_size, \n",
- " cluster_dir = cluster_dir,\n",
- " image_size = image_size,\n",
- " exit_if_exist = exit_if_exist,\n",
- " verbosity = progress_verbosity )\n",
- "\n",
- "# ---- Conclusion...\n",
- "\n",
- "directory = pathlib.Path(cluster_dir)\n",
- "s=sum(f.stat().st_size for f in directory.glob('**/*') if f.is_file())\n",
- "\n",
- "fidle.utils.subtitle('Ressources :')\n",
- "print('Duration : ',fidle.utils.hdelay(duration))\n",
- "print('Size : ',fidle.utils.hsize(s))\n",
- "\n",
- "fidle.utils.subtitle('Estimation with scale=1 :')\n",
- "print('Duration : ',fidle.utils.hdelay(duration*(1/scale)))\n",
- "print('Size : ',fidle.utils.hsize(s*(1/scale)))\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "---\n",
- "<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3.9.2 ('fidle-env')",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.2"
- },
- "vscode": {
- "interpreter": {
- "hash": "b3929042cc22c1274d74e3e946c52b845b57cb6d84f2d591ffe0519b38e4896d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/VAE/07-Check-CelebA.ipynb b/VAE/07-Check-CelebA.ipynb
deleted file mode 100644
index 38528da926244a8ddc6b833fd14f74b9ebf7c805..0000000000000000000000000000000000000000
--- a/VAE/07-Check-CelebA.ipynb
+++ /dev/null
@@ -1,273 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
- "\n",
- "# <!-- TITLE --> [VAE7] - Checking the clustered dataset\n",
- "<!-- DESC --> Episode : 3 Clustered dataset verification and testing of our datagenerator\n",
- "<!-- AUTHOR : Jean-Luc Parouty (CNRS/SIMaP) -->\n",
- "\n",
- "## Objectives :\n",
- " - Making sure our clustered dataset is correct\n",
- " - Do a little bit of python while waiting to build and train our VAE model.\n",
- "\n",
- "The [CelebFaces Attributes Dataset (CelebA)](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) contains about 200,000 images (202599,218,178,3). \n",
- "\n",
- "\n",
- "## What we're going to do :\n",
- "\n",
- " - Reload our dataset\n",
- " - Check and verify our clustered dataset"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 1 - Import and init\n",
- "### 1.2 - Import"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import pandas as pd\n",
- "\n",
- "import os,sys,glob\n",
- "import random\n",
- "\n",
- "from modules.datagen import DataGenerator\n",
- "\n",
- "import fidle\n",
- "\n",
- "# Init Fidle environment\n",
- "run_id, run_dir, datasets_dir = fidle.init('VAE7')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 1.2 - Parameters\n",
- "(Un)comment the right lines to be in accordance with the VAE6 notebook \n",
- "`image_size` : images size in the clusters, should be 128x128 or 192,160 - original size is (218,178) \n",
- "`progress_verbosity`: Verbosity of progress bar: 0=silent, 1=progress bar, 2=One line \n",
- "`enhanced_dir` : the place where clustered dataset was saved, can be :\n",
- "- `./data`, for tests purpose\n",
- "- `f{datasets_dir}/celeba/enhanced` in your datasets dir. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- Tests\n",
- "#\n",
- "image_size = (128,128)\n",
- "enhanced_dir = './data'\n",
- "\n",
- "# ----Full clusters generation\n",
- "#\n",
- "# image_size = (192,160)\n",
- "# enhanced_dir = f'{datasets_dir}/celeba/enhanced'\n",
- "\n",
- "progress_verbosity = 1"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- Used for continous integration - Just forget this line\n",
- "#\n",
- "fidle.override('image_size', 'enhanced_dir', 'progress_verbosity')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 2 - Data verification\n",
- "What we're going to do:\n",
- " - Recover all clusters by normalizing images\n",
- " - Make some statistics to be sure we have all the data\n",
- " - picking one image per cluster to check that everything is good."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- Return a legend from a description \n",
- "#\n",
- "def get_legend(x_desc,i):\n",
- " cols = x_desc.columns\n",
- " desc = x_desc.iloc[i]\n",
- " legend =[]\n",
- " for i,v in enumerate(desc):\n",
- " if v==1 : legend.append(cols[i])\n",
- " return str('\\n'.join(legend))\n",
- "\n",
- "chrono = fidle.Chrono()\n",
- "chrono.start()\n",
- "\n",
- "# ---- the place of the clusters files\n",
- "#\n",
- "lx,ly = image_size\n",
- "train_dir = f'{enhanced_dir}/clusters-{lx}x{ly}'\n",
- "\n",
- "# ---- get cluster list\n",
- "#\n",
- "clusters_name = [ os.path.splitext(f)[0] for f in glob.glob( f'{train_dir}/*.npy') ]\n",
- "\n",
- "# ---- Counters set to 0\n",
- "#\n",
- "imax = len(clusters_name)\n",
- "i,n1,n2,s = 0,0,0,0\n",
- "imgs,desc = [],[]\n",
- "\n",
- "# ---- Reload all clusters\n",
- "#\n",
- "fidle.utils.subtitle('Reload all clusters...')\n",
- "for cluster_name in clusters_name: \n",
- " \n",
- " # ---- Reload images and normalize\n",
- "\n",
- " x_data = np.load(cluster_name+'.npy')\n",
- " \n",
- " # ---- Reload descriptions\n",
- " \n",
- " x_desc = pd.read_csv(cluster_name+'.csv', header=0)\n",
- " \n",
- " # ---- Counters\n",
- " \n",
- " n1 += len(x_data)\n",
- " n2 += len(x_desc.index)\n",
- " s += x_data.nbytes\n",
- " i += 1\n",
- " \n",
- " # ---- Get somes images/legends\n",
- " \n",
- " j=random.randint(0,len(x_data)-1)\n",
- " imgs.append( x_data[j].copy() )\n",
- " desc.append( get_legend(x_desc,j) )\n",
- " x_data=None\n",
- " \n",
- " # ---- To appear professional\n",
- " \n",
- " fidle.utils.update_progress('Load clusters :',i,imax, redraw=True, verbosity=progress_verbosity)\n",
- "\n",
- "d=chrono.get_delay(format='seconds')\n",
- "\n",
- "fidle.utils.subtitle('Few stats :')\n",
- "print(f'Loading time : {d} s or {fidle.utils.hdelay(d)}')\n",
- "print(f'Number of cluster : {i}')\n",
- "print(f'Number of images : {n1}')\n",
- "print(f'Number of desc. : {n2}')\n",
- "print(f'Total size of img : {fidle.utils.hsize(s)}')\n",
- "\n",
- "fidle.utils.subtitle('Have a look (1 image/ cluster)...')\n",
- "fidle.scrawler.images(imgs,desc,x_size=2,y_size=2,fontsize=8,columns=7,y_padding=2.5, save_as='01-images_and_desc')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<div class='nota'>\n",
- " <b>Note :</b> With this approach, the use of data is much much more effective !\n",
- " <ul>\n",
- " <li>Data loading speed : <b>x 10</b> (81 s vs 16 min.)</li>\n",
- " </ul>\n",
- "</div>"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 3 - Using our DataGenerator\n",
- "We are going to use a \"dataset generator\", which is an implementation of [tensorflow.keras.utils.Sequence](https://www.tensorflow.org/api_docs/python/tf/keras/utils/Sequence) \n",
- "During the trainning, batches will be requested to our DataGenerator, which will read the clusters as they come in."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- Our DataGenerator\n",
- "\n",
- "data_gen = DataGenerator(train_dir, batch_size=32, debug=True, scale=0.2)\n",
- "\n",
- "# ---- We ask him to retrieve all batchs\n",
- "\n",
- "batch_sizes=[]\n",
- "for i in range( len(data_gen)):\n",
- " x,y = data_gen[i]\n",
- " batch_sizes.append(len(x))\n",
- "\n",
- "print(f'\\n\\ntotal number of items : {sum(batch_sizes)}')\n",
- "print(f'batch sizes : {batch_sizes}')\n",
- "print(f'Last batch shape : {x.shape}')\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "---\n",
- "<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3.9.2 ('fidle-env')",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.2"
- },
- "vscode": {
- "interpreter": {
- "hash": "b3929042cc22c1274d74e3e946c52b845b57cb6d84f2d591ffe0519b38e4896d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/VAE/08-VAE-with-CelebA-128x128.ipynb b/VAE/08-VAE-with-CelebA-128x128.ipynb
deleted file mode 100644
index f6540b2be39302a38dfcaff9efa672a7733980ed..0000000000000000000000000000000000000000
--- a/VAE/08-VAE-with-CelebA-128x128.ipynb
+++ /dev/null
@@ -1,451 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
- "\n",
- "# <!-- TITLE --> [VAE8] - Training session for our VAE with 128x128 images\n",
- "<!-- DESC --> Episode 4 : Training with our clustered datasets in notebook or batch mode\n",
- "<!-- AUTHOR : Jean-Luc Parouty (CNRS/SIMaP) -->\n",
- "\n",
- "## Objectives :\n",
- " - Build and train a VAE model with a large dataset in **small or medium resolution (70 to 140 GB)**\n",
- " - Understanding a more advanced programming model with **data generator**\n",
- "\n",
- "The [CelebFaces Attributes Dataset (CelebA)](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) contains about 200,000 images (202599,218,178,3). \n",
- "\n",
- "## What we're going to do :\n",
- "\n",
- " - Defining a VAE model\n",
- " - Build the model\n",
- " - Train it\n",
- " - Follow the learning process with Tensorboard\n",
- "\n",
- "## Acknowledgements :\n",
- "As before, thanks to **François Chollet** who is at the base of this example. \n",
- "See : https://keras.io/examples/generative/vae\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 1 - Init python stuff"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import matplotlib.pyplot as plt\n",
- "import sys\n",
- "\n",
- "from tensorflow import keras\n",
- "from tensorflow.keras import layers\n",
- "from tensorflow.keras.callbacks import TensorBoard\n",
- "\n",
- "from modules.models import VAE\n",
- "from modules.layers import SamplingLayer\n",
- "from modules.callbacks import ImagesCallback, BestModelCallback\n",
- "from modules.datagen import DataGenerator\n",
- "\n",
- "import fidle\n",
- "\n",
- "# Init Fidle environment\n",
- "run_id, run_dir, datasets_dir = fidle.init('VAE8')\n",
- "\n",
- "VAE.about()\n",
- "DataGenerator.about()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# To clean run_dir, uncomment and run this next line\n",
- "# ! rm -r \"$run_dir\"/images-* \"$run_dir\"/logs \"$run_dir\"/figs \"$run_dir\"/models ; rmdir \"$run_dir\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 2 - Parameters\n",
- "`scale` : with scale=1, we need 1'30s on a GPU V100 ...and >20' on a CPU ! \n",
- "`latent_dim` : 2 dimensions is small, but usefull to draw ! \n",
- "`fit_verbosity`: Verbosity of training progress bar: 0=silent, 1=progress bar, 2=One line \n",
- "\n",
- "`loss_weights` : Our **loss function** is the weighted sum of two loss:\n",
- " - `r_loss` which measures the loss during reconstruction. \n",
- " - `kl_loss` which measures the dispersion. \n",
- "\n",
- "The weights are defined by: `loss_weights=[k1,k2]` where : `total_loss = k1*r_loss + k2*kl_loss` \n",
- "In practice, a value of \\[.6,.4\\] gives good results here.\n",
- "\n",
- "\n",
- "Uncomment the right lines according to what you want."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fit_verbosity = 1\n",
- "\n",
- "# ---- For tests\n",
- "#\n",
- "scale = 0.1\n",
- "image_size = (128,128)\n",
- "enhanced_dir = './data'\n",
- "latent_dim = 300\n",
- "loss_weights = [.6,.4]\n",
- "batch_size = 64\n",
- "epochs = 15\n",
- "\n",
- "# ---- Training with a full dataset\n",
- "#\n",
- "# scale = 1.\n",
- "# image_size = (128,128)\n",
- "# enhanced_dir = f'{datasets_dir}/celeba/enhanced'\n",
- "# latent_dim = 300\n",
- "# loss_weights = [.6,.4]\n",
- "# batch_size = 64\n",
- "# epochs = 15\n",
- "\n",
- "# ---- Training with a full dataset of large images\n",
- "#\n",
- "# # scale = 1.\n",
- "# image_size = (192,160)\n",
- "# enhanced_dir = f'{datasets_dir}/celeba/enhanced'\n",
- "# latent_dim = 300\n",
- "# loss_weights = [.6,.4]\n",
- "# batch_size = 64\n",
- "# epochs = 15"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Override parameters (batch mode) - Just forget this cell"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.override('scale', 'image_size', 'enhanced_dir', 'latent_dim', 'loss_weights')\n",
- "fidle.override('batch_size', 'epochs', 'fit_verbosity')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 3 - Prepare data\n",
- "Let's instantiate our generator for the entire dataset."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 3.1 - Finding the right place"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "lx,ly = image_size\n",
- "train_dir = f'{enhanced_dir}/clusters-{lx}x{ly}'\n",
- "\n",
- "print('Train directory is :',train_dir)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 3.2 - Get a DataGenerator"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "data_gen = DataGenerator(train_dir, 32, scale=scale)\n",
- "\n",
- "print(f'Data generator is ready with : {len(data_gen)} batchs of {data_gen.batch_size} images, or {data_gen.dataset_size} images')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 4 - Build model\n",
- "Note: We conserve the geometry of our last convolutional output (shape_before_flattening) so that we can adapt the decoder to the encoder."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "#### Encoder"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "inputs = keras.Input(shape=(lx, ly, 3))\n",
- "x = layers.Conv2D(32, 3, strides=2, padding=\"same\", activation=\"relu\")(inputs)\n",
- "x = layers.Conv2D(64, 3, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.Conv2D(64, 3, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.Conv2D(64, 3, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "\n",
- "shape_before_flattening = keras.backend.int_shape(x)[1:]\n",
- "\n",
- "x = layers.Flatten()(x)\n",
- "x = layers.Dense(512, activation=\"relu\")(x)\n",
- "\n",
- "z_mean = layers.Dense(latent_dim, name=\"z_mean\")(x)\n",
- "z_log_var = layers.Dense(latent_dim, name=\"z_log_var\")(x)\n",
- "z = SamplingLayer()([z_mean, z_log_var])\n",
- "\n",
- "encoder = keras.Model(inputs, [z_mean, z_log_var, z], name=\"encoder\")\n",
- "encoder.compile()\n",
- "# encoder.summary()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "#### Decoder"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "inputs = keras.Input(shape=(latent_dim,))\n",
- "\n",
- "x = layers.Dense(np.prod(shape_before_flattening))(inputs)\n",
- "x = layers.Reshape(shape_before_flattening)(x)\n",
- "\n",
- "x = layers.Conv2DTranspose(64, 3, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.Conv2DTranspose(64, 3, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.Conv2DTranspose(64, 3, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.Conv2DTranspose(32, 3, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "outputs = layers.Conv2DTranspose(3, 3, padding=\"same\", activation=\"sigmoid\")(x)\n",
- "\n",
- "decoder = keras.Model(inputs, outputs, name=\"decoder\")\n",
- "decoder.compile()\n",
- "# decoder.summary()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "#### VAE\n",
- "Our loss function is the weighted sum of two values. \n",
- "`reconstruction_loss` which measures the loss during reconstruction. \n",
- "`kl_loss` which measures the dispersion. \n",
- "\n",
- "The weights are defined by: `r_loss_factor` : \n",
- "`total_loss = r_loss_factor*reconstruction_loss + (1-r_loss_factor)*kl_loss`\n",
- "\n",
- "if `r_loss_factor = 1`, the loss function includes only `reconstruction_loss` \n",
- "if `r_loss_factor = 0`, the loss function includes only `kl_loss` \n",
- "In practice, a value arround 0.5 gives good results here.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "vae = VAE(encoder, decoder, loss_weights)\n",
- "\n",
- "vae.compile(optimizer=keras.optimizers.Adam())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 5 - Train\n",
- "With `scale=1`, need 20' for 10 epochs on a V100 (IDRIS) \n",
- "...on a basic CPU, may be >40 hours !"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 5.1 - Callbacks"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "x_draw,_ = data_gen[0]\n",
- "data_gen.rewind()\n",
- "\n",
- "callback_images = ImagesCallback(x=x_draw, z_dim=latent_dim, nb_images=5, from_z=True, from_random=True, run_dir=run_dir)\n",
- "callback_bestmodel = BestModelCallback( run_dir + '/models/best_model.h5' )\n",
- "callback_tensorboard = TensorBoard(log_dir=run_dir + '/logs', histogram_freq=1)\n",
- "\n",
- "callbacks_list = [callback_images, callback_bestmodel]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 5.2 - Train it"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "chrono = fidle.Chrono()\n",
- "chrono.start()\n",
- "\n",
- "history = vae.fit(data_gen, epochs=epochs, batch_size=batch_size, callbacks=callbacks_list, verbose=fit_verbosity)\n",
- "\n",
- "chrono.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 6 - Training review\n",
- "### 6.1 - History"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.scrawler.history(history, plot={\"Loss\":['loss','r_loss', 'kl_loss']}, save_as='01-history')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 6.2 - Reconstruction during training"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "images_z, images_r = callback_images.get_images( range(0,epochs,2) )\n",
- "\n",
- "fidle.utils.subtitle('Original images :')\n",
- "fidle.scrawler.images(x_draw[:5], None, indices='all', columns=5, x_size=2,y_size=2, save_as='02-original')\n",
- "\n",
- "fidle.utils.subtitle('Encoded/decoded images')\n",
- "fidle.scrawler.images(images_z, None, indices='all', columns=5, x_size=2,y_size=2, save_as='03-reconstruct')\n",
- "\n",
- "fidle.utils.subtitle('Original images :')\n",
- "fidle.scrawler.images(x_draw[:5], None, indices='all', columns=5, x_size=2,y_size=2, save_as=None)\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 6.3 - Generation (latent -> decoder) during training"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.utils.subtitle('Generated images from latent space')\n",
- "fidle.scrawler.images(images_r, None, indices='all', columns=5, x_size=2,y_size=2, save_as='04-encoded')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "---\n",
- "<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3.9.2 ('fidle-env')",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.2"
- },
- "vscode": {
- "interpreter": {
- "hash": "b3929042cc22c1274d74e3e946c52b845b57cb6d84f2d591ffe0519b38e4896d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/VAE/09-VAE-with-CelebA-192x160.ipynb b/VAE/09-VAE-with-CelebA-192x160.ipynb
deleted file mode 100644
index 588cd50a449964baec923b1fbfe432933fd63ea0..0000000000000000000000000000000000000000
--- a/VAE/09-VAE-with-CelebA-192x160.ipynb
+++ /dev/null
@@ -1,461 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
- "\n",
- "# <!-- TITLE --> [VAE9] - Training session for our VAE with 192x160 images\n",
- "<!-- DESC --> Episode 4 : Training with our clustered datasets in notebook or batch mode\n",
- "<!-- AUTHOR : Jean-Luc Parouty (CNRS/SIMaP) -->\n",
- "\n",
- "## Objectives :\n",
- " - Build and train a VAE model with a large dataset in **medium resolution 140 GB**\n",
- " - Understanding a more advanced programming model with **data generator**\n",
- "\n",
- "The [CelebFaces Attributes Dataset (CelebA)](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) contains about 200,000 images (202599,218,178,3). \n",
- "\n",
- "## What we're going to do :\n",
- "\n",
- " - Defining a VAE model\n",
- " - Build the model\n",
- " - Train it\n",
- " - Follow the learning process with Tensorboard\n",
- "\n",
- "## Acknowledgements :\n",
- "As before, thanks to **François Chollet** who is at the base of this example. \n",
- "See : https://keras.io/examples/generative/vae\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 1 - Init python stuff"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import matplotlib.pyplot as plt\n",
- "import sys\n",
- "\n",
- "from tensorflow import keras\n",
- "from tensorflow.keras import layers\n",
- "from tensorflow.keras.callbacks import TensorBoard\n",
- "\n",
- "from modules.models import VAE\n",
- "from modules.layers import SamplingLayer\n",
- "from modules.callbacks import ImagesCallback, BestModelCallback\n",
- "from modules.datagen import DataGenerator\n",
- "\n",
- "import fidle\n",
- "\n",
- "# Init Fidle environment\n",
- "run_id, run_dir, datasets_dir = fidle.init('VAE9')\n",
- "\n",
- "VAE.about()\n",
- "DataGenerator.about()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# To clean run_dir, uncomment and run this next line\n",
- "# ! rm -r \"$run_dir\"/images-* \"$run_dir\"/logs \"$run_dir\"/figs \"$run_dir\"/models ; rmdir \"$run_dir\""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 2 - Parameters\n",
- "`scale` : With scale=1, we need 1'30s on a GPU V100 ...and >20' on a CPU ! \n",
- "`latent_dim` : 2 dimensions is small, but usefull to draw ! \n",
- "`fit_verbosity`: Verbosity of training progress bar: 0=silent, 1=progress bar, 2=One line \n",
- "\n",
- "`loss_weights` : Our **loss function** is the weighted sum of two loss:\n",
- " - `r_loss` which measures the loss during reconstruction. \n",
- " - `kl_loss` which measures the dispersion. \n",
- "\n",
- "The weights are defined by: `loss_weights=[k1,k2]` where : `total_loss = k1*r_loss + k2*kl_loss` \n",
- "In practice, a value of \\[.6,.4\\] gives good results here.\n",
- "\n",
- "\n",
- "Uncomment the right lines according to what you want."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [],
- "source": [
- "fit_verbosity = 1\n",
- "\n",
- "# ---- For tests\n",
- "\n",
- "scale = 0.01\n",
- "image_size = (192,160)\n",
- "enhanced_dir = './data'\n",
- "latent_dim = 300\n",
- "loss_weights = [.6,.4]\n",
- "batch_size = 64\n",
- "epochs = 5\n",
- "\n",
- "# ---- Training with a full dataset of large images\n",
- "#\n",
- "# scale = 1.\n",
- "# image_size = (192,160)\n",
- "# enhanced_dir = f'{datasets_dir}/celeba/enhanced'\n",
- "# latent_dim = 300\n",
- "# loss_weights = [.6,.4]\n",
- "# batch_size = 64\n",
- "# epochs = 15"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Override parameters (batch mode) - Just forget this cell"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.override('scale', 'image_size', 'enhanced_dir', 'latent_dim', 'loss_weights')\n",
- "fidle.override('batch_size', 'epochs', 'fit_verbosity')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 3 - Prepare data\n",
- "Let's instantiate our generator for the entire dataset."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 3.1 - Finding the right place"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "lx,ly = image_size\n",
- "train_dir = f'{enhanced_dir}/clusters-{lx}x{ly}'\n",
- "\n",
- "print('Train directory is :',train_dir)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 3.2 - Get a DataGenerator"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "data_gen = DataGenerator(train_dir, 32, scale=scale)\n",
- "\n",
- "print(f'Data generator is ready with : {len(data_gen)} batchs of {data_gen.batch_size} images, or {data_gen.dataset_size} images')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 4 - Build model\n",
- "Note: We conserve the geometry of our last convolutional output (shape_before_flattening) so that we can adapt the decoder to the encoder."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "#### Encoder"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "inputs = keras.Input(shape=(lx, ly, 3))\n",
- "x = layers.Conv2D(32, 4, strides=2, padding=\"same\", activation=\"relu\")(inputs)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.Conv2D(64, 4, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.Conv2D(128, 4, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.Conv2D(256, 4, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.Conv2D(512, 4, strides=2, padding=\"same\", activation=\"relu\")(x)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.Flatten()(x)\n",
- "\n",
- "z_mean = layers.Dense(latent_dim, name=\"z_mean\")(x)\n",
- "z_log_var = layers.Dense(latent_dim, name=\"z_log_var\")(x)\n",
- "z = SamplingLayer()([z_mean, z_log_var])\n",
- "\n",
- "encoder = keras.Model(inputs, [z_mean, z_log_var, z], name=\"encoder\")\n",
- "encoder.compile()\n",
- "# encoder.summary()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "#### Decoder"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "inputs = keras.Input(shape=(latent_dim,))\n",
- "\n",
- "x = layers.Dense(512*6*5)(inputs)\n",
- "x = layers.Reshape((6,5,512))(x)\n",
- "\n",
- "x = layers.UpSampling2D()(x)\n",
- "x = layers.Conv2D(512, kernel_size=3, strides=1, padding='same', activation='relu')(x)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.UpSampling2D()(x)\n",
- "x = layers.Conv2D(256, kernel_size=3, strides=1, padding='same', activation='relu')(x)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.UpSampling2D()(x)\n",
- "x = layers.Conv2D(128, kernel_size=3, strides=1, padding='same', activation='relu')(x)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.UpSampling2D()(x)\n",
- "x = layers.Conv2D(64, kernel_size=3, strides=1, padding='same', activation='relu')(x)\n",
- "x = layers.BatchNormalization(axis=1)(x)\n",
- "\n",
- "x = layers.UpSampling2D()(x)\n",
- "outputs = layers.Conv2D(3, kernel_size=3, strides=1, padding='same', activation='sigmoid')(x)\n",
- "\n",
- "decoder = keras.Model(inputs, outputs, name=\"decoder\")\n",
- "decoder.compile()\n",
- "# decoder.summary()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "#### VAE\n",
- "Our loss function is the weighted sum of two values. \n",
- "`reconstruction_loss` which measures the loss during reconstruction. \n",
- "`kl_loss` which measures the dispersion. \n",
- "\n",
- "The weights are defined by: `r_loss_factor` : \n",
- "`total_loss = r_loss_factor*reconstruction_loss + (1-r_loss_factor)*kl_loss`\n",
- "\n",
- "if `r_loss_factor = 1`, the loss function includes only `reconstruction_loss` \n",
- "if `r_loss_factor = 0`, the loss function includes only `kl_loss` \n",
- "In practice, a value arround 0.5 gives good results here.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "vae = VAE(encoder, decoder, loss_weights)\n",
- "\n",
- "vae.compile(optimizer=keras.optimizers.Adam())"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 5 - Train\n",
- "With `scale=1`, need 20' for 10 epochs on a V100 (IDRIS) \n",
- "...on a basic CPU, may be >40 hours !"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 5.1 - Callbacks"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "x_draw,_ = data_gen[0]\n",
- "data_gen.rewind()\n",
- "\n",
- "callback_images = ImagesCallback(x=x_draw, z_dim=latent_dim, nb_images=5, from_z=True, from_random=True, run_dir=run_dir)\n",
- "callback_bestmodel = BestModelCallback( run_dir + '/models/best_model.h5' )\n",
- "callback_tensorboard = TensorBoard(log_dir=run_dir + '/logs', histogram_freq=1)\n",
- "\n",
- "callbacks_list = [callback_images, callback_bestmodel]"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 5.2 - Train it"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "chrono = fidle.Chrono()\n",
- "chrono.start()\n",
- "\n",
- "history = vae.fit(data_gen, epochs=epochs, batch_size=batch_size, callbacks=callbacks_list, verbose=fit_verbosity)\n",
- "\n",
- "chrono.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 6 - Training review\n",
- "### 6.1 - History"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.scrawler.history(history, plot={\"Loss\":['loss','r_loss', 'kl_loss']}, save_as='01-history')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 6.2 - Reconstruction during training"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "images_z, images_r = callback_images.get_images( range(0,epochs,2) )\n",
- "\n",
- "fidle.utils.subtitle('Original images :')\n",
- "fidle.scrawler.images(x_draw[:5], None, indices='all', columns=5, x_size=2,y_size=2, save_as='02-original')\n",
- "\n",
- "fidle.utils.subtitle('Encoded/decoded images')\n",
- "fidle.scrawler.images(images_z, None, indices='all', columns=5, x_size=2,y_size=2, save_as='03-reconstruct')\n",
- "\n",
- "fidle.utils.subtitle('Original images :')\n",
- "fidle.scrawler.images(x_draw[:5], None, indices='all', columns=5, x_size=2,y_size=2, save_as=None)\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 6.3 - Generation (latent -> decoder) during training"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.utils.subtitle('Generated images from latent space')\n",
- "fidle.scrawler.images(images_r, None, indices='all', columns=5, x_size=2,y_size=2, save_as='04-encoded')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "---\n",
- "<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3.9.2 ('fidle-env')",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.2"
- },
- "vscode": {
- "interpreter": {
- "hash": "b3929042cc22c1274d74e3e946c52b845b57cb6d84f2d591ffe0519b38e4896d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/VAE/10-VAE-with-CelebA-post.ipynb b/VAE/10-VAE-with-CelebA-post.ipynb
deleted file mode 100644
index 3a602937e584ab65cef907a82d0f4f5be71d030e..0000000000000000000000000000000000000000
--- a/VAE/10-VAE-with-CelebA-post.ipynb
+++ /dev/null
@@ -1,407 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "<img width=\"800px\" src=\"../fidle/img/00-Fidle-header-01.svg\"></img>\n",
- "\n",
- "# <!-- TITLE --> [VAE10] - Data generation from latent space\n",
- "<!-- DESC --> Episode 5 : Exploring latent space to generate new data\n",
- "<!-- AUTHOR : Jean-Luc Parouty (CNRS/SIMaP) -->\n",
- "\n",
- "## Objectives :\n",
- " - New data generation from **latent space**\n",
- " - Understanding of underlying principles\n",
- " - Guided image generation, **latent morphing**\n",
- " - Model management\n",
- " \n",
- "Here again, we don't consume data anymore, but we generate them ! ;-)\n",
- "\n",
- "\n",
- "The [CelebFaces Attributes Dataset (CelebA)](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) contains about 200,000 images (202599,218,178,3)... \n",
- "...But our data is now in the imagination of our network!\n",
- "\n",
- "## What we're going to do :\n",
- " - Load a saved model\n",
- " - Reconstruct some images from latent space\n",
- " - Matrix of generated images"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 1 - Init python stuff"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "import numpy as np\n",
- "import pandas as pd\n",
- "import scipy.stats\n",
- "from skimage import io, transform\n",
- "import os,sys,importlib\n",
- "import math\n",
- "from importlib import reload\n",
- "\n",
- "import matplotlib\n",
- "import matplotlib.pyplot as plt\n",
- "\n",
- "from scipy.stats import norm\n",
- "\n",
- "from modules.datagen import DataGenerator\n",
- "from modules.models import VAE\n",
- "\n",
- "# Init Fidle environment\n",
- "import fidle\n",
- "\n",
- "run_id, run_dir, datasets_dir = fidle.init('VAE10')\n",
- "\n",
- "VAE.about()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 2 - Parameters\n",
- "**Note :** We only have one set of data, used for training. \n",
- "We did not separate our data between learning and testing because our goal is to generate data.\n",
- "\n",
- "Define these parameters according to the clustered dataset you wish to use...\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# --- Tests\n",
- "#\n",
- "image_size = (128,128)\n",
- "enhanced_dir = './data'\n",
- "models_dir = './run/VAE8'\n",
- "\n",
- "# --- Full clusters (128,128)\n",
- "#\n",
- "# image_size = (128,128)\n",
- "# enhanced_dir = f'{datasets_dir}/celeba/enhanced'\n",
- "# models_dir = './run/VAE8'\n",
- "\n",
- "# ---- Full clusters (192,160)\n",
- "#\n",
- "# image_size = (192,160)\n",
- "# enhanced_dir = f'{datasets_dir}/celeba/enhanced'\n",
- "# models_dir = './run/VAE9'\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- Used for continous integration - Just forget this line\n",
- "#\n",
- "fidle.override('image_size', 'enhanced_dir', 'models_dir')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 3 - Gets some data"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# ---- the place of the clusters files\n",
- "\n",
- "lx,ly = image_size\n",
- "train_dir = f'{enhanced_dir}/clusters-{lx}x{ly}'\n",
- "dataset_csv = f'{datasets_dir}/celeba/origine/list_attr_celeba.csv'\n",
- "dataset_img = f'{datasets_dir}/celeba/origine/img_align_celeba'\n",
- "\n",
- "# ---- Get images (one cluster)\n",
- "\n",
- "x_data = np.load(f'{train_dir}/images-000.npy')\n",
- "\n",
- "# ---- Get descriptions\n",
- "\n",
- "dataset_desc = pd.read_csv(dataset_csv, header=0)\n",
- "\n",
- "print('Data directory is :',train_dir)\n",
- "print('Images retrieved :',len(x_data))\n",
- "print('Descriptions :',len(dataset_desc))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 4 - Reload best model"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "vae=VAE()\n",
- "vae.reload(f'{models_dir}/models/best_model')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 5 - Image reconstruction"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "n_show = 8\n",
- "np.random.shuffle(x_data)\n",
- "\n",
- "# ---- Get latent points and reconstructed images\n",
- "\n",
- "# y_reconst = vae.predict(x_data)\n",
- "\n",
- "z_mean, z_log_var, z_data = vae.encoder.predict(x_data)\n",
- "y_reconst = vae.decoder.predict(z_data)\n",
- "\n",
- "# ---- Just show it\n",
- "\n",
- "fidle.scrawler.images(x_data[:10], None, columns=10, x_size=1.5,y_size=1.5, spines_alpha=0.1, save_as='01-original')\n",
- "fidle.scrawler.images(y_reconst[:10], None, columns=10, x_size=1.5,y_size=1.5, spines_alpha=0.1, save_as='02-reconstruct')\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 6 - Latent space distribution"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "z_dim = z_data.shape[1]\n",
- "x = np.linspace(-3, 3, 100)\n",
- "\n",
- "fig = plt.figure(figsize=(12, 10))\n",
- "fig.subplots_adjust(hspace=0.3, wspace=0.2)\n",
- "\n",
- "for i in range(40):\n",
- " ax = fig.add_subplot(4, 10, i+1)\n",
- " ax.hist(z_data[:,i], density=True, bins = 20)\n",
- " ax.axis('off')\n",
- " ax.set_xlim(-3,3)\n",
- " ax.text(0.5, -0.2, str(i), fontsize=14, ha='center', transform=ax.transAxes)\n",
- " ax.plot(x,norm.pdf(x))\n",
- "\n",
- "fidle.scrawler.save_fig('03-latent-space')\n",
- "plt.show()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 7 - Generation of new faces"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "n_new = 48\n",
- "\n",
- "z_new = np.random.normal( loc=0,scale=0.7,size=(n_new,z_dim) )\n",
- "x_new = vae.decoder.predict(z_new)\n",
- "\n",
- "fidle.scrawler.images(x_new, None, columns=6, x_size=2,y_size=2.4, spines_alpha=0,y_padding=0, save_as='04-new-faces')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Step 8 - Playing with latent space\n",
- "### 8.1 - The attributes of our images"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.utils.subtitle('Dataset description file (csv) :')\n",
- "display(dataset_desc.head())\n",
- "\n",
- "fidle.utils.subtitle('Defined attributes :')\n",
- "for i,v in enumerate(dataset_desc.columns):\n",
- " print(f'{v:24}', end='')\n",
- " if (i+1) % 4 == 0 :print('')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 8.2 Let's find some predictable images"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "def get_latent_vector(images_desc, vector_size=50):\n",
- " \"\"\"\n",
- " Get a set of images, give them to the encoder and return an mean vector\n",
- " args:\n",
- " images_desc : Images descrption\n",
- " return:\n",
- " mean(z)\n",
- " \"\"\"\n",
- "\n",
- " # ---- Get filenames of given images descriptions\n",
- " \n",
- " filenames=images_desc['image_id'][:vector_size]\n",
- " \n",
- " # ---- Retrieve images\n",
- " \n",
- " imgs=[]\n",
- " print(f'Read {vector_size} images...', end='')\n",
- " for i,filename in enumerate(filenames):\n",
- " filename = f'{dataset_img}/{filename}'\n",
- " img = io.imread(filename)\n",
- " img = transform.resize(img, image_size)\n",
- " imgs.append( img )\n",
- " print('done.')\n",
- " \n",
- " # ---- Get latent space vectors\n",
- "\n",
- " x_images=np.array(imgs)\n",
- " z_mean, z_log_var, z = vae.encoder.predict(x_images)\n",
- " \n",
- " # ---- return mean vector\n",
- " \n",
- " return z.mean(axis=0)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "df = dataset_desc\n",
- "\n",
- "z11 = get_latent_vector( df.loc[ (df['Male'] == -1) & (df['Smiling']== 1) & (df['Blond_Hair']== 1)] )\n",
- "z12 = get_latent_vector( df.loc[ (df['Male'] == -1) & (df['Smiling']== 1) & (df['Black_Hair']== 1)] )\n",
- "z21 = get_latent_vector( df.loc[ (df['Male'] == 1) & (df['Smiling']==-1) & (df['Black_Hair']== 1)] )\n",
- "\n",
- "labels=['Woman\\nBlond hair\\nSmiling','Woman\\nBlack hair\\nSmiling','Man\\nBlack Hair\\nNot smiling']\n",
- "\n",
- "\n",
- "z_images = np.array( [z11,z12,z21] )\n",
- "x_images = vae.decoder.predict( z_images, verbose=0 )\n",
- "fidle.scrawler.images(x_images,labels,columns=3,x_size=3,y_size=3,spines_alpha=0, save_as='05-predictable')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "### 8.3 - And do somme latent morphing !"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "\n",
- "n=6\n",
- "dj=(z12-z11)/n\n",
- "di=(z21-z11)/n\n",
- "\n",
- "z=[]\n",
- "for i in range(n):\n",
- " for j in range(n):\n",
- " z.append( z11+di*i+dj*j )\n",
- "\n",
- "x_images = vae.decoder.predict( np.array(z) )\n",
- "fidle.scrawler.images(x_images,columns=n,x_size=2,y_size=2.4,y_padding=0,spines_alpha=0, save_as='06-morphing')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "fidle.end()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "---\n",
- "<img width=\"80px\" src=\"../fidle/img/00-Fidle-logo-01.svg\"></img>"
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3.9.2 ('fidle-env')",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.9.2"
- },
- "vscode": {
- "interpreter": {
- "hash": "b3929042cc22c1274d74e3e946c52b845b57cb6d84f2d591ffe0519b38e4896d"
- }
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/VAE/batch_slurm.sh b/VAE/batch_slurm.sh
deleted file mode 100755
index 0b4000dfa403df9cc7e43e05f65f6bfd56255dd6..0000000000000000000000000000000000000000
--- a/VAE/batch_slurm.sh
+++ /dev/null
@@ -1,84 +0,0 @@
-#!/bin/bash
-# -----------------------------------------------
-# _ _ _
-# | |__ __ _| |_ ___| |__
-# | '_ \ / _` | __/ __| '_ \
-# | |_) | (_| | || (__| | | |
-# |_.__/ \__,_|\__\___|_| |_|
-# Fidle at IDRIS
-# -----------------------------------------------
-#
-# <!-- TITLE --> [VAE10] - SLURM batch script
-# <!-- DESC --> Bash script for SLURM batch submission of VAE8 notebooks
-# <!-- AUTHOR : Jean-Luc Parouty (CNRS/SIMaP) -->
-#
-# Soumission : sbatch /(...)/fidle/VAE/batch_slurm.sh
-# Suivi : squeue -u $USER
-
-# ==== Job parameters ==============================================
-
-#SBATCH --job-name="VAE" # nom du job
-#SBATCH --ntasks=1 # nombre de tâche (un unique processus ici)
-#SBATCH --gres=gpu:1 # nombre de GPU à réserver (un unique GPU ici)
-#SBATCH --cpus-per-task=10 # nombre de coeurs à réserver (un quart du noeud)
-#SBATCH --hint=nomultithread # on réserve des coeurs physiques et non logiques
-#SBATCH --time=01:00:00 # temps exécution maximum demande (HH:MM:SS)
-#SBATCH --output="VAE_%j.out" # nom du fichier de sortie
-#SBATCH --error="VAE_%j.err" # nom du fichier d'erreur (ici commun avec la sortie)
-#SBATCH --mail-user=Jean-Luc.Parouty@grenoble-inp.fr
-#SBATCH --mail-type=ALL
-
-# ==== Notebook parameters =========================================
-
-MODULE_ENV="tensorflow-gpu/py3/2.4.0"
-NOTEBOOK_DIR="$WORK/fidle/VAE"
-
-# ---- VAE MNIST
-#
-# NOTEBOOK_SRC="01-VAE-with-MNIST.ipynb"
-# FIDLE_OVERRIDE_VAE8_run_dir="./run/MNIST.$SLURM_JOB_ID"
-
-# ---- VAE CelebA
-#
-NOTEBOOK_SRC="08-VAE-with-CelebA.ipynb"
-#
-export FIDLE_OVERRIDE_VAE8_run_dir="./run/CelebA.$SLURM_JOB_ID"
-export FIDLE_OVERRIDE_VAE8_scale="1"
-export FIDLE_OVERRIDE_VAE8_image_size="(128,128)"
-export FIDLE_OVERRIDE_VAE8_enhanced_dir='{datasets_dir}/celeba/enhanced'
-export FIDLE_OVERRIDE_VAE8_loss_weights="[.5,.5]"
-export FIDLE_OVERRIDE_VAE8_epochs="8"
-
-# ---- By default (no need to modify)
-#
-NOTEBOOK_OUT="${NOTEBOOK_SRC%.*}==${SLURM_JOB_ID}==.ipynb"
-
-# ==================================================================
-
-echo '------------------------------------------------------------'
-echo "Start : $0"
-echo '------------------------------------------------------------'
-echo "Job id : $SLURM_JOB_ID"
-echo "Job name : $SLURM_JOB_NAME"
-echo "Job node list : $SLURM_JOB_NODELIST"
-echo '------------------------------------------------------------'
-echo "Notebook dir : $NOTEBOOK_DIR"
-echo "Notebook src : $NOTEBOOK_SRC"
-echo "Notebook out : $NOTEBOOK_OUT"
-echo "Environment : $MODULE_ENV"
-echo '------------------------------------------------------------'
-env | grep FIDLE_OVERRIDE | awk 'BEGIN { FS = "=" } ; { printf("%-35s : %s\n",$1,$2) }'
-echo '------------------------------------------------------------'
-
-# ---- Module
-
-module purge
-module load "$MODULE_ENV"
-
-# ---- Run it...
-
-cd $NOTEBOOK_DIR
-
-jupyter nbconvert --ExecutePreprocessor.timeout=-1 --to notebook --output "$NOTEBOOK_OUT" --execute "$NOTEBOOK_SRC"
-
-echo 'Done.'
diff --git a/fidle/about.yml b/fidle/about.yml
index 101115aa24b2a257da817f4a3f85be552d935477..e5112a485f466b5267f8d3661c16b02f00c61db2 100644
--- a/fidle/about.yml
+++ b/fidle/about.yml
@@ -13,7 +13,7 @@
#
# This file describes the notebooks used by the Fidle training.
-version: 2.2.3
+version: 2.2.4
content: notebooks
name: Notebooks Fidle
description: All notebooks used by the Fidle training
@@ -28,12 +28,14 @@ toc:
IRIS: Perceptron Model 1957
BHPD: Basic regression using DN
MNIST: Basic classification using a DN
- GTSRB: Images classification with Convolutional Neural Networks (CNN
+ GTSRB: Images classification with Convolutional Neural Networks (CNN)
IMDB: Sentiment analysis with word embeddin
- SYNOP: Time series with Recurrent Neural Network (RNN
+ SYNOP: Time series with Recurrent Neural Network (RNN)
Transformers: Sentiment analysis with transformer
- AE: Unsupervised learning with an autoencoder neural network (AE
- VAE: Generative network with Variational Autoencoder (VAE
- DCGAN: Generative Adversarial Networks (GANs
- DRL: Deep Reinforcement Learning (DRL
+ AE: Unsupervised learning with an autoencoder neural network (AE)
+ VAE: Generative network with Variational Autoencoder (VAE)
+ DCGAN: Generative Adversarial Networks (GANs)
+ DDPM: Diffusion Model (DDPM)
+ Optimization: Training optimization
+ DRL: Deep Reinforcement Learning (DRL)
Misc: Miscellaneous
diff --git a/fidle/ci/default.yml b/fidle/ci/default.yml
index 9b2d3393832190bd4f71e3039d105b5469105ca3..b0d14991c93a12f7d6fb0afcda6bffd6ba28aa33 100644
--- a/fidle/ci/default.yml
+++ b/fidle/ci/default.yml
@@ -1,6 +1,6 @@
campain:
version: '1.0'
- description: Automatically generated ci profile (19/12/22 10:48:06)
+ description: Automatically generated ci profile (12/04/23 09:28:57)
directory: ./campains/default
existing_notebook: 'remove # remove|skip'
report_template: 'fidle # fidle|default'
@@ -275,54 +275,6 @@ VAE3:
scale: default
seed: default
models_dir: default
-VAE5:
- notebook: VAE/05-About-CelebA.ipynb
- overrides:
- progress_verbosity: default
-VAE6:
- notebook: VAE/06-Prepare-CelebA-datasets.ipynb
- overrides:
- progress_verbosity: default
- scale: default
- seed: default
- cluster_size: default
- image_size: default
- output_dir: default
- exit_if_exist: default
-VAE7:
- notebook: VAE/07-Check-CelebA.ipynb
- overrides:
- image_size: default
- enhanced_dir: default
- progress_verbosity: default
-VAE8:
- notebook: VAE/08-VAE-with-CelebA-128x128.ipynb
- overrides:
- scale: default
- image_size: default
- enhanced_dir: default
- latent_dim: default
- loss_weights: default
- batch_size: default
- epochs: default
- fit_verbosity: default
-VAE9:
- notebook: VAE/09-VAE-with-CelebA-192x160.ipynb
- overrides:
- scale: default
- image_size: default
- enhanced_dir: default
- latent_dim: default
- loss_weights: default
- batch_size: default
- epochs: default
- fit_verbosity: default
-VAE10:
- notebook: VAE/10-VAE-with-CelebA-post.ipynb
- overrides:
- image_size: default
- enhanced_dir: default
- models_dir: default
#
# ------------ DCGAN
@@ -346,6 +298,18 @@ SHEEP2:
num_img: default
fit_verbosity: default
+#
+# ------------ DDPM
+#
+DDPM1:
+ notebook: DDPM/01-ddpm.ipynb
+
+#
+# ------------ Optimization
+#
+OPT1:
+ notebook: Optimization/01-Apprentissages-rapides-et-Optimisations.ipynb
+
#
# ------------ DRL
#